
Logical Scribbles
[기계학습] K-means Clustering 에 대하여 본문

이번 포스팅에서는 기계학습 이론에서 자주 나오는 K-means Clustering에 대해 알아보자.
기계학습은 지도학습과 비지도 학습, 크게 두가지로 나뉜다. 지도 학습은 선생님이 문제를 내고 그 다음 바로 정답까지 같이 알려주는 방식의 학습 방법이고, 비지도 학습은 정답 라벨이 없는 데이터를 비슷한 특징끼리 군집화 하여 새로운 데이터에 대한 결과를 예측하는 것이다.
이번에 소개하는 K-means clustering, K-means 군집화는 비지도학습 방법 중 하나이다. 쉽게 말해 정답 라벨이 없는 데이터를 비슷한 특징을 갖는 K개의 군집으로 군집화 하는 알고리즘이다.
K-means 군집화의 알고리즘은 다음과 같다.
- K개의 군집의 중심점(centroid)을 임의로 선택한다.
- 각 데이터 포인트들을 가장 가까운 클러스터 중심점에 할당한다.
- 할당된 데이터 포인트들의 평균값을 계산하여 새로운 클러스터 중심점을 업데이트한다.
- 2-3단계를 반복한다. 클러스터 할당이 변하지 않거나, 미리 정한 반복 횟수에 도달하면 알고리즘이 종료된다.
이제 이 알고리즘을 살펴보자.

첫번째로, K개의 군집의 중심점을 임의로 선택한다. 말 그대로 랜덤인데, 이 때 전체 데이터에서 임의로 K개의 점을 선택하여 초기 중심점으로 설정하여도 되고, 전체 solution space에서 K개의 좌표를 선택해도 된다.

두번째로, 각 데이터에서 K개의 중심점까지의 거리를 구한다음, 특정 중심점을 가장 가까운 거리로 갖는 데이터들을 군집화 한다.

세번째로, 한 군집의 중심점을 그 군집의 모든 데이터들의 평균적인 좌표로 옮긴다. 그리고 첫번째, 두번째, 세번째 과정을 반복한다.
마지막으로, 클러스터 할당이 변하지 않거나, 미리 정한 반복 횟수에 도달하면 알고리즘이 종료된다.
전체적인 과정을 보면 다음과 같다.

여기까지 이해하면 의문이 생긴다.
과연 데이터를 적절히 군집화 하는 K 값은 어떻게 찾는가?
이 최적의 K를 찾는 방법에는 두가지가 있다.
1. 엘보우(Elbow) 기법
엘보우 기법은 군집의 수를 늘렸을 때 중심점 간의 평균 거리가 더 이상 많이 감소하지 않는 경우의 K를 선택하는 방법이다. 일반적으로 군집의 개수가 늘 때마다 중심점 간의 평균 거리가 급격히 감소하는데, 적절한 K가 발견되면 이 평균거리가 매우 천천히 감소하는 것을 이용한 것이다.
그래프 상에서 이 부분이 팔꿈치랑 닮아서 엘보우 기법이라고 한다.참고로, 클러스터 개수가 적으면 중심점 간의 거리가 매우 커지며, 적절한 개수이면 거리가 점점 짧아진다. 개수가 많으면 평균 거리가 매우 조금씩 줄어든다.

2. 실루엣(Silhouette) 기법
실루엣 기법은 각 데이터의 실루엣 계수를 이용하는 방법이다. 실루엣 계수는 개별 데이터가 할당된 군집 내 데이터와 얼마나 가깝게 군집화 되어있는지, 그리고 다른 군집에 있는 데이터와는 얼마나 멀리 분리되어 있는지를 나타내는 수치이다. 클러스터의 개수가 최적화되어 있으면 실루엣 계수는 1에 가까운 값이 된다. 실루엣 계수를 구하는 과정은 다음과 같다.
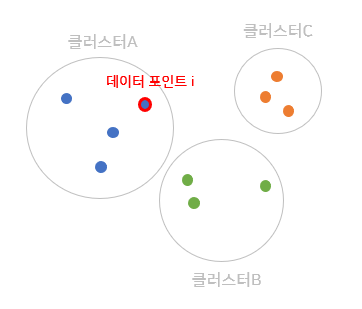
먼저, 군집 A의 한개의 데이터 포인트를 잡는다.

두번째로, 선택한 데이터 포인트에서 같은 군집에 속한 점들과의 거리의 평균을 구한다.

세번째로, 선택한 데이터 포인트에서 다른 군집 B에 속한 점들과의 거리의 평균을 구한다.

네번째로, 선택한 데이터 포인트에서 다른 군집 C에 속한 점들과의 거리의 평균을 구한다.

다섯번째로, 선택한 데이터 포인트에서 거리가 가장 가까운 다른 군집과의 거리를 선택하고
(이 상황에서 데이터 포인트와 클러스터 B와의 거리는 5.3, C와의 거리는 5.8이므로 B와의 거리 5.3를 선택)
1).자신의 클러스터 안에서의 평균 거리와 2).선택한 다른 군집과의 거리를 비교하여 더 큰 값을 분모에 써준 뒤, 분자에는 그 두개의 값을 빼서 데이터 포인트 i의 실루엣 계수를 구한다.

위 그림처럼 모든 데이터 포인트들에 대해 실루엣 계수를 계산했다면, 모든 실루엣 계수들의 평균값(overall average silhouette width)을 계산해준다. 만일 클러스터 개수별로 여러 번 군집화를 수행했거나, 여러 클러스터링 기법으로 여러 번 군집화를 수행한 경우 클러스터의 개수에 대한 실루엣 계수를 plotting 하여 K를 선택할 수 있다.

Pracrical한 측면에서, 실루엣 계수의 평균이 0.7보다 크면 잘 분류되었다고 본다. 또한 엘보우 기법에 비해 계산하는데 시간이 굉장히 오래 걸린다고 한다.
끝!