
Logical Scribbles
[딥러닝] RNN(Recurrent Neural Network)이란? 본문

이번 포스팅에서는 가장 기본적인 인공 시퀀스 모델인 RNN에 대해 알아보자. RNN을 한글로 풀어서 쓰면 '순환 신경망'이 된다. 즉 network 안에서 '순환'하는 무언가가 핵심인 모델이라는 것인데, 이 '순환'이 의미하는 바에 초점을 두고 알아보도록 하자.
번역기를 만든다고 생각해보자. 번역기에 주어지는 입력은 번역하고자 하는 문장이다. 문장은 '단어의 시퀀스'이다. 여기서 '시퀀스'란 말 그대로 순서가 있는 데이터를 가리킨다. 즉 번역기의 인풋은 단어가 순서대로 배열되어 있는 데이터이다. 이와 같이 시퀀스 데이터를 처리하기 위해 고안된 모델을 시퀀스 모델이라고 한다. 마찬가지로 주식의 가격은 시간에 따라 변화하므로 주가를 예측하고자 할 때에도 시퀀스 모델을 사용해야할 것이다.
이러한 시퀀스 모델 중 인공 신경망 시퀀스 모델의 가장 기본적인 모델이 RNN이다. RNN 이후에 등장하는 LSTM이나 GRU도 기회가 되면 공부하여 포스팅 해보도록 하겠다.
1. RNN 기초
지금까지 공부했던 NN을 생각해보자. 어떤 값이 주어졌을 때 그 값은 활성함수를 통과하며 출력층 방향으로만 진행한다. 이와 같은 NN을 '피드 포워드 신경망'이라고 한다. RNN은 피드 포워드 신경망이 아닌 모델 중 하나이다. 즉, 어떤 값이 주어졌을 때 모든 값들이 출력층 방향으로만 진행하지 않는다는 것이다. 특히 RNN은 hidden layer의 노드에서 활성 함수를 통과한 출력값이 다시 hidden layer의 계산의 입력으로 보내지도록 설계되었다.
이 과정을 간단하게 그림으로 보면 다음과 같다.

x_t는 t 시점에서의 RNN 모델로의 인풋을 의미하고, h_t는 출력층의 출력 벡터이다. (bias는 잠시 무시하자.)
여기서 출력값이 다시 hidden layer의 계산의 입력으로 보내지는 것이 핵심이다. 위의 그림에서 분명하게 t-1 시점에서의 출력값이 t 시점의 인풋 계산에 영향을 주고 있을 것이다. 또한, t-1 시점에서의 계산은 t-2 시점의 출력값에 영향을 받고 있을 것이다. 이렇게 어떤 시점에서 hidden layer 안에서의 계산은 그 시점 바로 전의 hidden layer 출력값에 영향을 받는다.
이러한 바로 전 시점이 다음 시점에게 보내는 값을 Hidden state라고 한다.
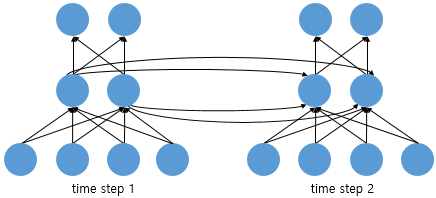
이를 그림으로 표현하면 아래와 같고, 위의 그림을 펼친 형태가 된다.

RNN에 입력값 [x0,x1,...,xt]를 '순차적'으로 입력하였을 때 나오는 결과값은 [h0,h1,...ht]이다. 이 때 중요한 포인트는 모두 같은 RNN 계층을 사용한다는 것이다. 즉, 같은 weight를 공유한다. 만약 다른 weight를 사용한다면 t+1개의 인풋에 대하여 서로 다른 weight을 사용하므로 모델이 상당히 복잡해질 것이다.
RNN을 뉴런 관점에서 보면 다음과 같은 구조를 갖는다.
RNN은 입력과 출력의 길이를 다르게 설계할 수 있으며 따라서 다양한 용도로 사용될 수 있다. 대표적으로 세가지 형태(용도)가 있다.
1) 일대다 (one-to-many)

대표적으로 '이미지 캡셔닝'을 할 때 일 대 다 형태를 사용한다. 이미지 캡셔닝이란 한 개의 사진 입력 데이터에 대해 사진의 제목을 출력하는 것을 말한다.
2) 다대일 (many-to-one)

다 대 일 구조는 입력되는 문장에 따라 감정 분류 혹은 스펨메일 분류 등을 할 때 사용된다.
3) 다대다 (many-to-many)

이 구조가 번역기 모델에 쓰일 수 있는 구조다. 한글로 된 문장(한글 단어의 시퀀스)의 인풋에 대해, 영어로 된 문장(영단어 시퀀스)를 출력하게 할 수 있다.
2. RNN 자세히 살펴보기
1) 순전파

시점 t에서의 hidden layer의 출력값을 h_t라고 하자. 시점 t에서 h_t를 구하기 위해서는 해당 시점에서의 입력값 x_t와 이전 시점에서 hidden layer의 출력값 h_t-1이 필요하다. 또한 h_t를 구하기 위해서 두개의 가중치가 필요한데, x_t에 대한 가중치를 W_x라고 하고, h_t-1에 대한 가중치를 W_h라고 하자.
h_t는 h_t-1 과 x_t 와의 weighted sum이 비선형 함수를 통과시켜 계산한다.
또한 t 시점에서의 아웃풋 y_t는 이러한 h_t와 W_y를 이용하여 비선형 함수를 통과시켜 계산한다.
지금까지의 내용을 정리해보면 다음과 같다.

h_t를 출력하기 위한 활성함수로는 보통 tanh를 사용한다고 한다.
y_t를 출력하기 위한 활성함수는 task에 따라 다른데, 이진분류 상황에서는 시그모이드, 다중분류 상황에서는 소프트맥스를 사용할 수 있을 것이다.
이제 예를 들어 살펴보자.

우리의 task는 "You say goodbye and I say hello" 라는 문장을 한글로 번역하는 것이다.
왼쪽 아래의 그림을 보면 h_you와 say가 입력으로 들어오고 있다. 이 시점 이전에 이미 h_you는 활성함수를 통과하여 한글 단어로 번역이 되었을 것이다. h_you와 say가 RNN에서 계산되어 h_say가 출력되고, h_say 또한 활성함수를 통과하여 한글 단어로 번역이 될 것이다. 그 다음 시점에는 h_say와 hello가 입력되어 RNN상에서 계산된 뒤 h_hello를 출력한다.
h_say와 hello를 입력받아 RNN에서 일어나는 일은 오른쪽 위 그림을 보면 된다. 정확히 아래의 식을 그대로 따르고 있음을 알 수 있을 것이다.

hello가 입력되는 시점 역시 h_hello가 계산되어 다음 시점의 인풋이 된다. 이때 h_hello는 그동안 입력되어온 단어들의 정보를 압축적으로 가지고 있는 인풋이 된다.
2) 역전파
어찌됐든 RNN도 학습을 해야할 것이다. 역시 학습을 위해 역전파(Back propagation)을 사용하는데, 이 과정을 살펴보도록 하자.

- Softmax 이후 나오는 단어들의 확률과 정답간의 차이를 Cross Entropy를 사용하여 측정한다. (오차 측정)
- 이후 이 오차를 미분하여 dh_hello, dh_say, dh_row, dW_x , dW_h, dx_hello, dx_say, dh_I 등을 구하고, 가중치에 반영하여 학습시킨다.
대표적으로 인풋 "hello" 에 대한 출력값 y_hello를 미분하는 과정은 다음과 같다.

3) 장기 의존성 문제(기울기 소실) & 기울기 폭발 문제
이처럼 RNN은 시퀀스 데이터 처리에 유용할 수 있지만 치명적인 단점이 존재하는데, 그것이 장기 의존성, 기울기 소실, 기울기 폭발 문제이다.
앞서 말했듯이 RNN에 입력되는 hidden state는 이전의 모든 입력에 대한 정보를 가지고 있다.

예를 들어 물음표에 들어갈 단어를 예측하고 싶을 때, 물음표를 출력하기 위한 입력으로 이전의 모든 단어들에 대한 정보가 압축되어 들어간다. 이제 이 예측에 대한 역전파 과정을 보자.

위의 그림처럼 기울기는 RNN 계층의 과거 시점으로 전달되고, 이 때 과거 층들에 "의미 있는 기울기"가 전달되어야 시간 방향의 의존 관계를 제대로 학습할 수 있다. 즉, 역전파되는 Hidden state에 대한 기울기에 유의미한 정보가 있어야 하고, 그것이 과거로 잘 전달되어야 장기 의존 관계를 학습할 수 있다는 말이다.
만약 이 기울기가 중간에 소실되거나 과도하게 커진다면 (활성 함수의 특징으로 인해 흔히 있을 수 있는 문제이다.) 모델은 장기의존 관계를 학습할 수 없다.

3-1) 기울기 소실 문제
RNN의 장기 의존성 문제는 기울기 소실 때문에 발생한다.
아래 그림에서 E101을 h1에 대해 미분한 값에 주목해 보자.

E101을 h1에 대해 미분한 값을 얻기 위해서는 chain rule에 의해 엄청나게 많은 항들이 곱해져야 함을 알 수 있다. 만약 이 항들의 값이 1보다 작다면 곱해진 값은 매우 작아져서 거의 소실될 것이며, 1보다 크다면 항들이 곱해진 값은 폭발적으로 증가할 것이다.
은닉층에서의 활성함수로 쓰이는 tanh는 최대 미분값이 1이다. 즉, tanh의 미분값은 1보다 작을 확률이 매우 크다는 것이다. 만약 어떤 가중치(문장의 초반 단어들에 대한 가중치가 될 것이다.)를 업데이트하기 위해 chain rule에 의해 많은 항들이 계산되어 곱해져야 한다면 이 tanh를 통과한 많은 값들이 곱해질 것이고, 이는 곧 기울기 소실 문제로 이어져 제대로 된 학습이 되지 않을 수 있다.
3-2) 기울기 폭발 문제
RNN에서는 기울기 폭발도 쉽게 일어날 수 있다.

노란색 박스에 주목하자. 결론부터 말하면 행렬 곱 연산이 기울기 폭발의 원인이다.
역전파 과정에서 x_t 쪽의 역방향으로 자신과 dot 연산이 수행되는 W_x의 전치행렬을, W_x쪽의 역방향으로는 자신과 dot 연산이 수행되는 x_t의 전치행렬을 행렬곱 해줌을 알 수 있다.
즉 역전파 과정에서 이러한 행렬곱 연산이 계속해서 수행되는 것인데, 만약 이 행렬곱에 의한 결과가 1보다 큰 값이라면, 기울기 폭발이 일어날 수 있는 것이다.
이러한 RNN의 문제점들을 해결하기 위해 등장한 모델이 LSTM이다. 이는 기회가 되면 공부하여 포스팅 해보도록 하겠다.
끝!
'딥러닝 > 딥러닝 이론' 카테고리의 다른 글
| [딥러닝] 어텐션 메커니즘(Attention Mechanism)이란? (1) | 2023.11.27 |
|---|---|
| [딥러닝] Seq2Seq 와 거자일소(去者日疎 ) (1) | 2023.11.25 |
| [객체 탐지] NMS (Non-Maximum Suppression) (0) | 2023.11.21 |
| [객체 인식] Selective Search란? (Selective search for object recognition. IJCV, 2013) (0) | 2023.11.20 |
| [객체 탐지] Hard Negative Mining 이란? (0) | 2023.11.20 |



