
Logical Scribbles
[PyTorch] Cosine Annealing Warm Up Restarts 본문
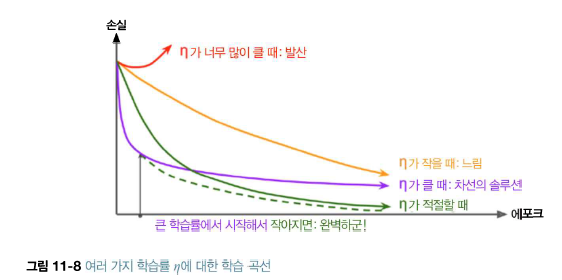
논문을 읽다보면 학습 과정에서 'Learning rate schedule'를 사용하는 경우를 많이 볼 수 있다. 나는 개인적으로 VPT를 학습시킬 때 모델의 정확도를 최대한 높이기 위해 다양한 scheduler를 사용해 보았다.
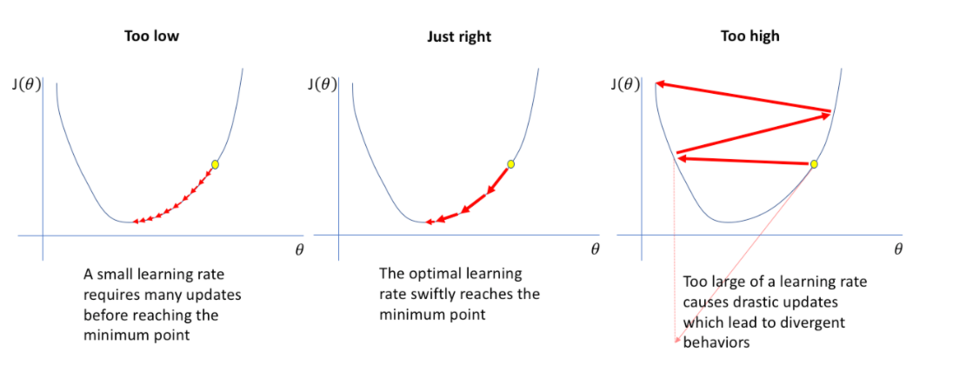
딥러닝을 처음 배울 때 혹은 gradient descent 방식을 배울 때 자주 접했을 그림이다. Back propagation을 진행할 때 learning rate를 정하게 되는데, 이 값에 따라 학습의 성능 혹은 속도가 많이 달라진다.
위의 그림에서 맨 왼쪽 그림은 learning rate가 너무 낮을 때 발생할 수 있는 상황을 보여준다. 너무 낮은 값은 많은 가중치 업데이트를 유발하고, 이는 학습을 위한 자원을 많이 소비할 가능성이 있다. 제일 오른쪽 그림은 learning rate가 너무 클 때 발생하며, gradient method에서 너무 큰 보폭만큼 가중치를 움직이게 되어 지그재그로 에러가 올라가는 상황이다.
가운데 그림은 정확히 우리가 원하는 상황으로, oprimal한 learning rate을 사용하여 가중치가 적절히 minimum point에 안착하는 상황이다. 모델을 학습 시키는 입장에서 가운데 상황만을 원하는 것이 일반적일 것이다.
그러면 어떻게 적절한 learning rate을 선택할 것인가? 이 질문에 답하기 위해 많은 수학자와 똑똑하신 분들이 많은 방법을 만들어 놓았다. Learning rate에 대한 선택지는 대표적으로 다음의 것들이 있다.
- 고정 학습률 (Fixed Learning Rate): 학습률이 학습 전체 과정 동안 변하지 않는다. (보통 처음 딥러닝을 배울 때 gradient descent를 고정 학습률을 이용한 식을 통해 배우는 것 같다.) 이 방식은 가장 간단하지만, 위의 그림처럼 때때로 최적의 결과를 얻기 어려울 수 있다.
- 단계 감소 (Step Decay): 특정 에폭마다 학습률을 일정 비율로 감소시킨다. 예를 들어, 매 10개 에폭마다 학습률을 반으로 줄이는 방식이 있다.
- 지수 감소 (Exponential Decay): 학습률이 지수 함수를 따라 감소한다. 이는 학습 초기에는 빠르게 감소하고, 시간이 지남에 따라 감소 속도가 느려진다.
- 사이클링 학습률 (Cyclical Learning Rates): 학습률이 최소값과 최대값 사이에서 주기적으로 변화한다. 이 방법은 local minima에서 탈출하는 데 도움이 될 수 있다.
- Warm Up을 포함한 scheduler: 'warm up' 기법과 결합된 learning rate scheduler 이다. 초기에는 학습률을 점차적으로 증가시킨 후, 특정 전략에 따라 감소시킨다.
이번 포스팅에서는 위의 다양한 방식 중 Warm UP을 포함한 scheduler를 중점으로 알아보자. 특히, 'Cosine Annealing Warm Up Restarts' 이라는 방식을 살펴볼 것이다.
파이토치에서는 다양한 learning rate scheduler를 제공하고 있다. 그 중 Cosine Annealing Warm Up Restarts에 대한 설명을 가져왔다.

Cosine Annealing Warm Up Restarts은 코사인 어닐링 + Warm Up이 결합된 학습률 스케줄러이다.
1. Cosine Annealing
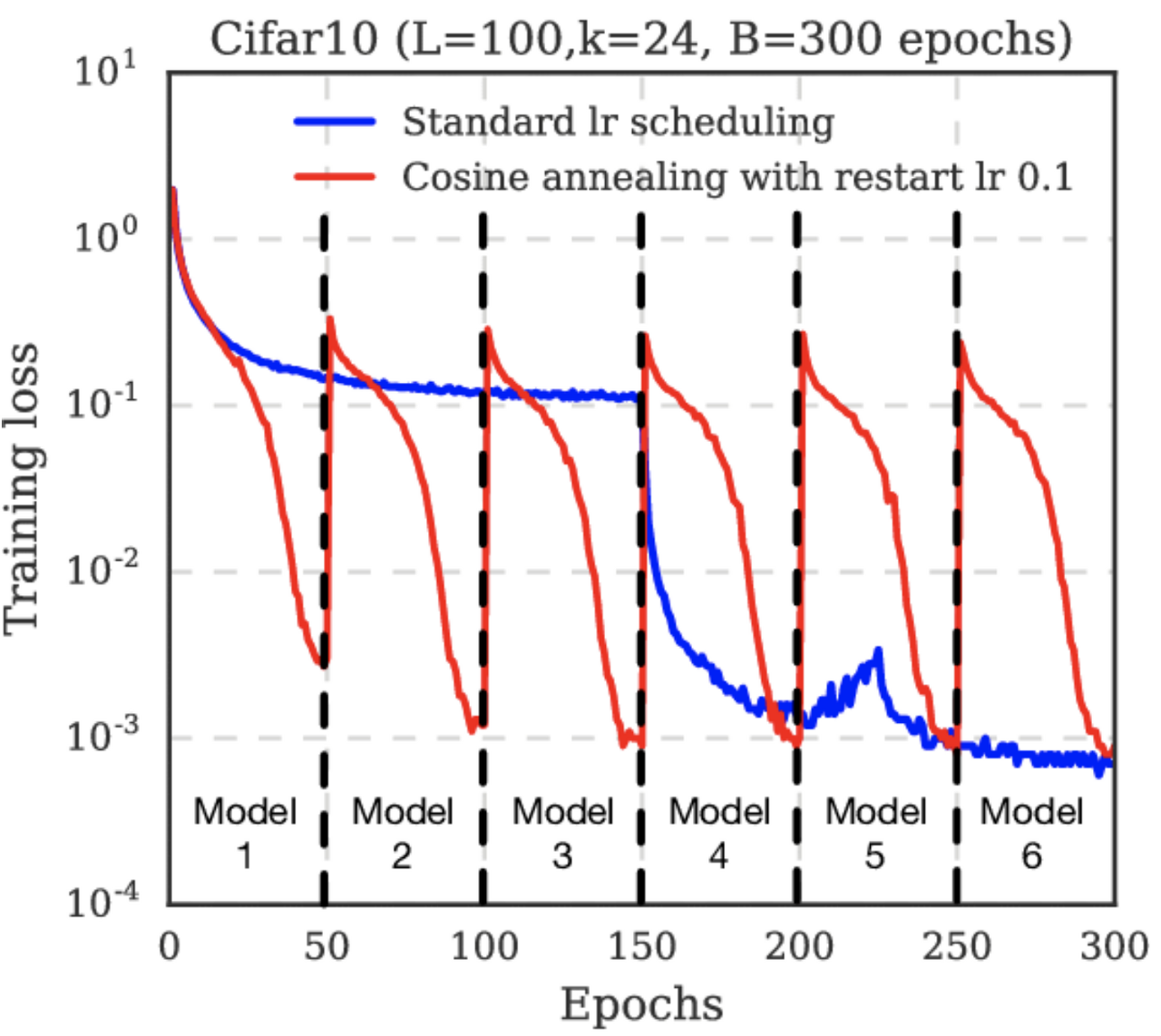
코사인 어닐링은 'SGDR'이라는 논문(아래 아카이브)에서 제안된 방식으로, learning rate의 맥시멈 값과 미니멈 값을 정해서 그 범위 안에서의 학습율을 코싸인 함수를 이용하여 조정하는 방법이다. 코사인 어닐링은 최대값과 최소값 사이에서 코싸인 함수를 이용하여 급격히 증가시켰다가 급격히 감소시키 때문에 모델의 매니폴드 공간의 안장점과 학습 정체 구간을 효과적으로 탈출 할 수 있다.
SGDR: Stochastic Gradient Descent with Warm Restarts
Restart techniques are common in gradient-free optimization to deal with multimodal functions. Partial warm restarts are also gaining popularity in gradient-based optimization to improve the rate of convergence in accelerated gradient schemes to deal with
arxiv.org
이러한 코사인 어닐링을 사용할 때 설정 해주어야할 변수가 몇가지 있다. 아래 코사인 어닐링에서의 학습률 수식을 보자.
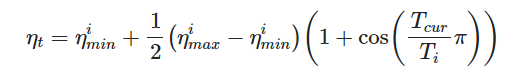
총 4가지의 변수가 있음을 확인할 수 있다.
- η_min , η_max : learning rate의 최대값과 최소값을 설정해준다.
- T_cur: Restart 이후 경과한 에포크의 수 (Restart는 학습률이 감소했다가 다시 높은 학습률에서 시작하는 것을 의미)
- T_i: 코사인 어닐링의 주기
2. Warm Up
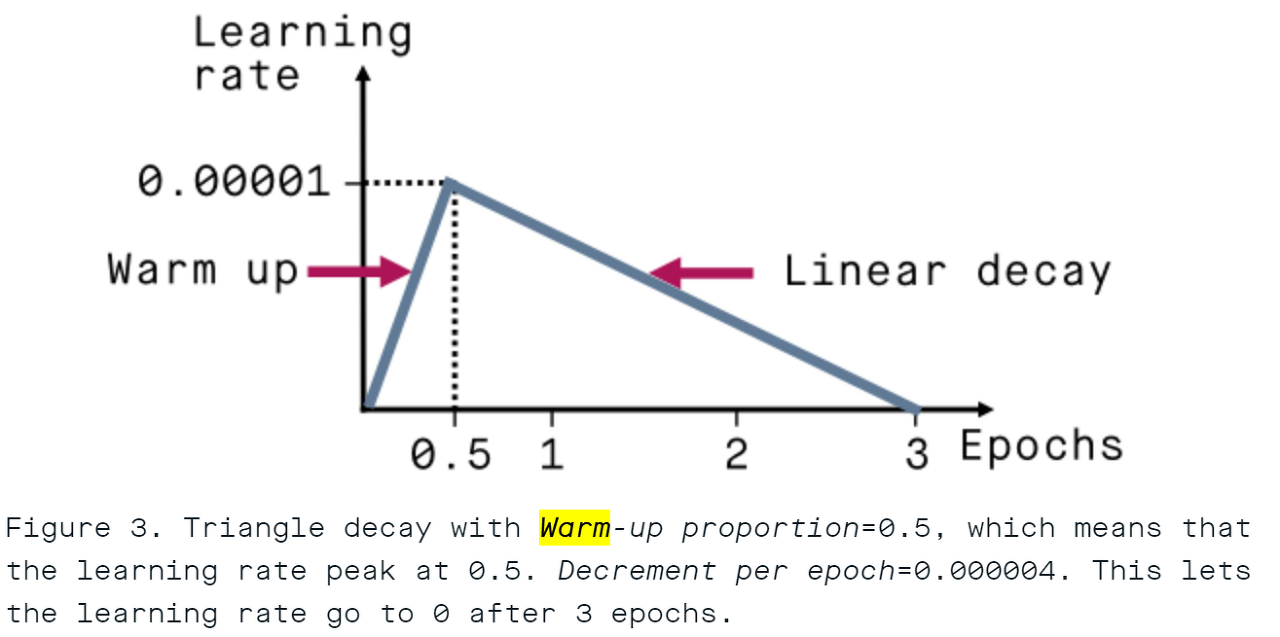
Warm Up의 친숙한 뜻은 '준비 운동'이다. 그렇다면 학습 시에도 일종의 준비 운동을 시킨다는 것인데, 이는 무슨 뜻일까?
만약 학습 시켜야 하는 데이터 세트가 매우 differentiated 되어 있다면 (특성과 목적에 따라 잘 분리가 되어 있다면), 일종의 "조기 과적합"으로 고통 받을 수 있다. 만약 강력한 특징을 가진 데이터가 포함되어 있다면, 모델의 초기 훈련은 해당 특징으로 심하게 왜곡되거나 또는 더 나쁘게는 주제와 전혀 관련이 없는 부수적인 특징으로 왜곡될 수 있다.
또한 딥러닝 시 보통 초기 파라미터는 랜덤하게 설정하기 때문에 초기부터 큰 학습률은 학습의 불안정을 초래할 수 있다.
따라서 Warm Up이 없으면 원하는 convergence를 얻기 위해 몇 가지 추가 에포크를 실행해야 할 수도 있다.
즉 Warm Up은 일종의 regularization의 역할을 한다고 볼 수 있다.
3. Implementation
파이토치에서는 Cosine Annealing Warm Up Restart를 제공하고 있다.
torch.optim — PyTorch 2.1 documentation
torch.optim torch.optim is a package implementing various optimization algorithms. Most commonly used methods are already supported, and the interface is general enough, so that more sophisticated ones can also be easily integrated in the future. How to us
pytorch.org

이번에는 파이토치 상에서 제공하는 코사인 어닐링 학습률 스케줄러에 대한 parameter에 대해 살펴보자.
- optimizer (Optimizer) – Wrapped optimizer.
- T_0 (int) – Number of iterations for the first restart.
- T_mult (int, optional) – A factor increases after a restart. Default: 1.
- eta_min (float, optional) – Minimum learning rate. Default: 0.
- last_epoch (int, optional) – The index of last epoch. Default: -1.
- verbose (bool) – If True, prints a message to stdout for each update. Default: False.
구현은 매우 간단하다.
scheduler = CosineAnnealingWarmRestarts(optimizer, T_0= period,
T_mult=period_mult , eta_min= min_learning_rate)
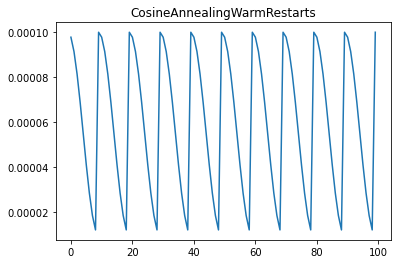
위 코드는 위 그래프와 같이 작동한다.
그러나 이 파이토치에서 제공하는 스케줄러는 약간의 아쉬움이 남는데, 아래 그림과 같이 학습률을 조정할 수 없기 때문이다.

즉 Warm Up start가 구현되어 있지 않고 학습률의 최댓값이 감소하는 방법이 구현되어 있지 않기 때문이다. 따라서 많은 사람들이 Custom Cosine Annealing Warm Up Restart 클래스를 정의해서 사용하는데, 아래의 깃허브에 잘 정리되어 있다.
katsura-jp/pytorch-cosine-annealing-with-warmup
import math
import torch
from torch.optim.lr_scheduler import _LRScheduler
class CosineAnnealingWarmupRestarts(_LRScheduler):
"""
optimizer (Optimizer): Wrapped optimizer.
first_cycle_steps (int): First cycle step size.
cycle_mult(float): Cycle steps magnification. Default: -1.
max_lr(float): First cycle's max learning rate. Default: 0.1.
min_lr(float): Min learning rate. Default: 0.001.
warmup_steps(int): Linear warmup step size. Default: 0.
gamma(float): Decrease rate of max learning rate by cycle. Default: 1.
last_epoch (int): The index of last epoch. Default: -1.
"""
def __init__(self,
optimizer : torch.optim.Optimizer,
first_cycle_steps : int,
cycle_mult : float = 1.,
max_lr : float = 0.1,
min_lr : float = 0.001,
warmup_steps : int = 0,
gamma : float = 1.,
last_epoch : int = -1
):
assert warmup_steps < first_cycle_steps
self.first_cycle_steps = first_cycle_steps # first cycle step size
self.cycle_mult = cycle_mult # cycle steps magnification
self.base_max_lr = max_lr # first max learning rate
self.max_lr = max_lr # max learning rate in the current cycle
self.min_lr = min_lr # min learning rate
self.warmup_steps = warmup_steps # warmup step size
self.gamma = gamma # decrease rate of max learning rate by cycle
self.cur_cycle_steps = first_cycle_steps # first cycle step size
self.cycle = 0 # cycle count
self.step_in_cycle = last_epoch # step size of the current cycle
super(CosineAnnealingWarmupRestarts, self).__init__(optimizer, last_epoch)
# set learning rate min_lr
self.init_lr()
def init_lr(self):
self.base_lrs = []
for param_group in self.optimizer.param_groups:
param_group['lr'] = self.min_lr
self.base_lrs.append(self.min_lr)
def get_lr(self):
if self.step_in_cycle == -1:
return self.base_lrs
elif self.step_in_cycle < self.warmup_steps:
return [(self.max_lr - base_lr)*self.step_in_cycle / self.warmup_steps + base_lr for base_lr in self.base_lrs]
else:
return [base_lr + (self.max_lr - base_lr) \
* (1 + math.cos(math.pi * (self.step_in_cycle-self.warmup_steps) \
/ (self.cur_cycle_steps - self.warmup_steps))) / 2
for base_lr in self.base_lrs]
def step(self, epoch=None):
if epoch is None:
epoch = self.last_epoch + 1
self.step_in_cycle = self.step_in_cycle + 1
if self.step_in_cycle >= self.cur_cycle_steps:
self.cycle += 1
self.step_in_cycle = self.step_in_cycle - self.cur_cycle_steps
self.cur_cycle_steps = int((self.cur_cycle_steps - self.warmup_steps) * self.cycle_mult) + self.warmup_steps
else:
if epoch >= self.first_cycle_steps:
if self.cycle_mult == 1.:
self.step_in_cycle = epoch % self.first_cycle_steps
self.cycle = epoch // self.first_cycle_steps
else:
n = int(math.log((epoch / self.first_cycle_steps * (self.cycle_mult - 1) + 1), self.cycle_mult))
self.cycle = n
self.step_in_cycle = epoch - int(self.first_cycle_steps * (self.cycle_mult ** n - 1) / (self.cycle_mult - 1))
self.cur_cycle_steps = self.first_cycle_steps * self.cycle_mult ** (n)
else:
self.cur_cycle_steps = self.first_cycle_steps
self.step_in_cycle = epoch
self.max_lr = self.base_max_lr * (self.gamma**self.cycle)
self.last_epoch = math.floor(epoch)
for param_group, lr in zip(self.optimizer.param_groups, self.get_lr()):
param_group['lr'] = lr
이는 아래와 같은 parameter만 조절하며 pip install로 간단하게 사용할 수 있다.
pip install 'git+https://github.com/katsura-jp/pytorch-cosine-annealing-with-warmup'
- optimizer (Optimizer): Wrapped optimizer.
- first_cycle_steps (int): First cycle step size.
- cycle_mult(float): Cycle steps magnification. Default: 1.
- max_lr(float): First cycle's max learning rate. Default: 0.1.
- min_lr(float): Min learning rate. Default: 0.001.
- warmup_steps(int): Linear warmup step size. Default: 0.
- gamma(float): Decrease rate of max learning rate by cycle. Default: 1.
- last_epoch (int): The index of last epoch. Default: -1.
>> from cosine_annealing_warmup import CosineAnnealingWarmupRestarts
>>
>> model = ...
>> optimizer = optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=1e-5) # lr is min lr
>> scheduler = CosineAnnealingWarmupRestarts(optimizer,
first_cycle_steps=200,
cycle_mult=1.0,
max_lr=0.1,
min_lr=0.001,
warmup_steps=50,
gamma=1.0)
>> for epoch in range(n_epoch):
>> train()
>> valid()
>> scheduler.step()'딥러닝 > PyTorch' 카테고리의 다른 글
| [PyTorch] 파이토치 Torchvision.transforms 를 이용하여 이미지 갖고 놀아보기 (1) | 2023.11.14 |
|---|
