
Logical Scribbles
[논문 리뷰] Gradient-Based Learning Applied to Document Recognization(LeNet-5) - 시대 배경 그리고 구조 본문
[논문 리뷰] Gradient-Based Learning Applied to Document Recognization(LeNet-5) - 시대 배경 그리고 구조
KimJake 2023. 11. 11. 11:15LeNet-5의 구조만 훑으며 읽고 싶다면 바로 3. LeNet-5를 읽으시면 됩니다.
이번에는 CNN에서의 조상급 논문에 대해 알아보자. 논문을 읽어보기 전, 이 논문이 탄생하게 된 시대 배경을 알고 있으면 더 도움이 될 것 같다.
1. 시대 배경

1. 1950년대, 시각피질 구조에 대한 연구가 진행되었다. 실험은 고양이를 이용하였고, 고양이에게 시각 정보가 주어졌을 때, 고양이의 뉴런들에 대해 관찰하는 것이었다. 결과적으로 고양이의 시야에 자극이 들어왔을 때, 전체 뉴런이 아닌 특정한 부분의 뉴런만이 활성화 되는 것을 알게 되었다. 즉, 고양이의 시각 피질 안의 뉴런들은 일정한 시각적 자극에만 반응하는 '국부 수용 영역 (Local receptive field)' 를 갖는다는 것을, 그리고 이 국부 수용 영역들이 서로 겹쳐져 전체적인 시야를 형성한다는 것을 알게 되었다.
2. 이 때 당시 이 논문의 저자 Yann LeCun 팀은 손글씨로 적힌 우편 번호의 기계적 분류에 관심이 있었다. 만약 우편 번호를 기계 스스로 분류 할 수 있게 된다면, 우체국 입장에서는 분류에 필요한 시간과 인건비를 줄일 수 있었을 것이다. 당시의 전통적인 분류 기법(hand-crafted algorithm)을 대체할 수 있는 보다 효율적인 machine을 원했고, 그 때 당시부터 large databases의 이용 가능성이 높아지면서 data들을 이용하여 기계 스스로 학습할 수 있는 모델을 만들고자 했다.
이러한 배경 등으로 Yann LeCun 팀은 1998년 'Gradient-Based Learning Applied to Document Recognization' 이라는 논문을 발표하게 되고, 이 논문에서 CNN(Convolutional Neural Network)을 적용한 LeNet-5라는 모델을 세상에 내놓게 된다. 사실 이 논문 이전에 LeCun의 팀이 10년전 1989년에 발표한 논문 ' Backpropagation applied to handwritten zip code recognition ' 에서 CNN이 먼저 소개되긴 하였지만, 이 논문에서 CNN을 LeNet-5라는 모델에 적용하여 소개했다.
2. Traditional pattern recognition
LeNet-5에 대해 소개하기 앞서 소개했던 그 시대의 Pattern Recognition 방식에 대하여 다시 짚고 넘어가보자.
전통적인 기법의 pattern recognition의 과정은 다음과 같다.
Feature Extraction Module 이라고 불리는 첫번째 모듈에 input data가 들어간다. 우편 번호가 손글씨로 적혀있는 사진이라고 생각해도 되겠다. Feature Extraction Module은 입력 받은 데이터가 저차원의 벡터나 짧은 기호 등으로 표현될 수 있도록 약간의 변형을 취해준다. 그렇게 함으로써 처음의 input data는 1) 간단하게 matched, compared 될 수 있고, 2) 그들의 본질을 바꾸지 않는 왜곡이나 변형에 상대적으로 잘 견디게 된다.
두번째 Classifier Module은 훈련이 가능하다. 다른 말로 말하면 학습이 가능한 모듈이다. 이렇게 두개의 모듈을 통과한 input data의 class가 예측된다.
이 모듈의 가장 큰 문제점은 사전 지식이 필요하다는 것이다. 특히 첫번째 모듈을 설계하려면 사람의 노력이 필요하다. 즉, 사람이 한땀 한땀 모듈을 설계해야 한다는 점이다. 전체적인 분류 과정에 있어서 디자이너가 feature을 어떻게 세팅하냐 등에 따라 machine의 성능이 변화할 수 있고, 이러한 작업은 새로운 task가 주어졌을 때 또 다시 사람이 직접 해내야 하는 아주 귀찮은 작업이다.
사람은 게으름의 동물인 것 같다. 아무튼 엄청나게 귀찮은 이 작업을, LeCun 팀은 machine이 대체할 수 있게 하고 싶었다.
이 때 당시 학습 가능한 classifier의 learning technique은 점점 변화하고 있었는데, 그 변화의 중심에 있던 것이 바로 Multi-layer Neural Network with back propagation이다. 이렇게 back propagtion이 떠오르게 된 이유 3가지도 논문에 설명되어 있는데, 1) Back propagation을 할 때 local minima에 빠지는 현상이 그리게 나쁜게 아니라는 사실, 2) non-linear system에서의 back-propagation algorithm이 가능하다는 사실, 3) Neural Network에서 back propagtion이 효과적이라는 사실이 알려졌기 때문이다.
이 논문은 Gradient Based neural network가 같은 데이터로 학습한 다른 machine들 보다 성능이 뛰어남을 주장하고 있다. 그리고 그 중 가장 최고의 성능을 자랑하는 것이 바로 Convolutional Neural Network라고 한다. 이 CNN은 feature extraction을 위해 학습이 가능하다.
3. LeNet-5
이제 드디어 이러한 CNN을 탑재한 LeNet-5 에 대해 살펴보도록 하자. 이 부분이 이 글을 쓰는 이유이기도 하다.
우선 LeNet-5는 Layer C1~F6까지 Activation Function으로 hyperbolic tangent를 사용한다.
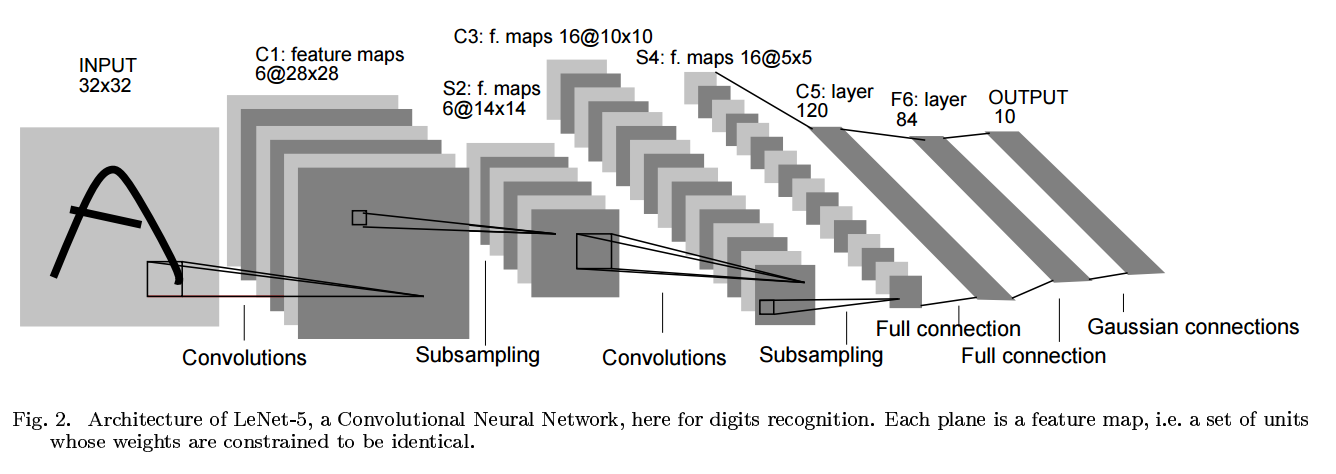
(1) Input Data
LeNet-5는 총 7개의 layer로 구성되어 있다. 모든 layer는 학습 가능한 parameter들로 구성되어 있고, input으로는 32*32 pixel image가 입력되게 된다. (이 size는 database에 있는 가장 큰 character 보다 크다고 한다.)
이렇게 더 큰 사이즈의 pixel image를 넣는 이유는, stroke end-point 또는 corner와 같은 잠재적인 독특한 특징이 highest level의 feature detector의 수용 영역의 중앙에 나타날 수 있기 때문이다.
input pixel 들은 흰색,검은색에 따라 정규화 되어 있다. (white corresponds to -0.1, black corresponds to 1.175) 따라서 전체적인 인풋의 평균은 0, 분산은 1에 가깝게 설정된다.
앞으로의 layer 설명에서, 숫자 앞에 C가 붙은 layer는 convolution layer, S가 붙은 layer는 Subsampling layer, F가 붙은 layer는 fully connected layer를 의미한다.
Layer에 대한 설명은 개인적으로 중요하다고 생각되니 논문과 함께 읽어보며 알아보자.
(2) Layer C1 (Convolutional Layer)

Layer C1은 convolutional layer이고, 6개의 feature map이 존재한다. feature map의 각각의 unit은 인풋의 5*5의 데이터들과 연결되어 있다. feature map의 크기는 28*28이다. C1은 156개의 학습가능한 parameter로 구성되고, 122,304개의 connection이 존재한다.

(3) Layer S2 (Subsampling Layer)

Layer S2는 Sub-sampling Layer(나에게는 Pooling이 더 익숙하다)이고, 6개의 14*14 feature map으로 구성되어 있다. feature map의 각각의 unit은 C1의 2*2 데이터들과 연결되어 있다. 이러한 2*2 인풋, 즉 4개의 인풋은 더해지고, 훈련 가능한 coefficient와 곱해지고, 훈련 가능한 bias와 더해진 후 S자형 함수를 통과함으로서 만들어진다.
이러한 2*2 수용 영역은 서로 겹치지 않아서, S2에서의 feature map은 C1에서의 feature map과 비교했을 때, 행과 열의 수가 모두 절반이 된다.
Layer S2의 학습 가능한 parameter는 12개이고, 5,880개의 connection이 존재한다고 한다.
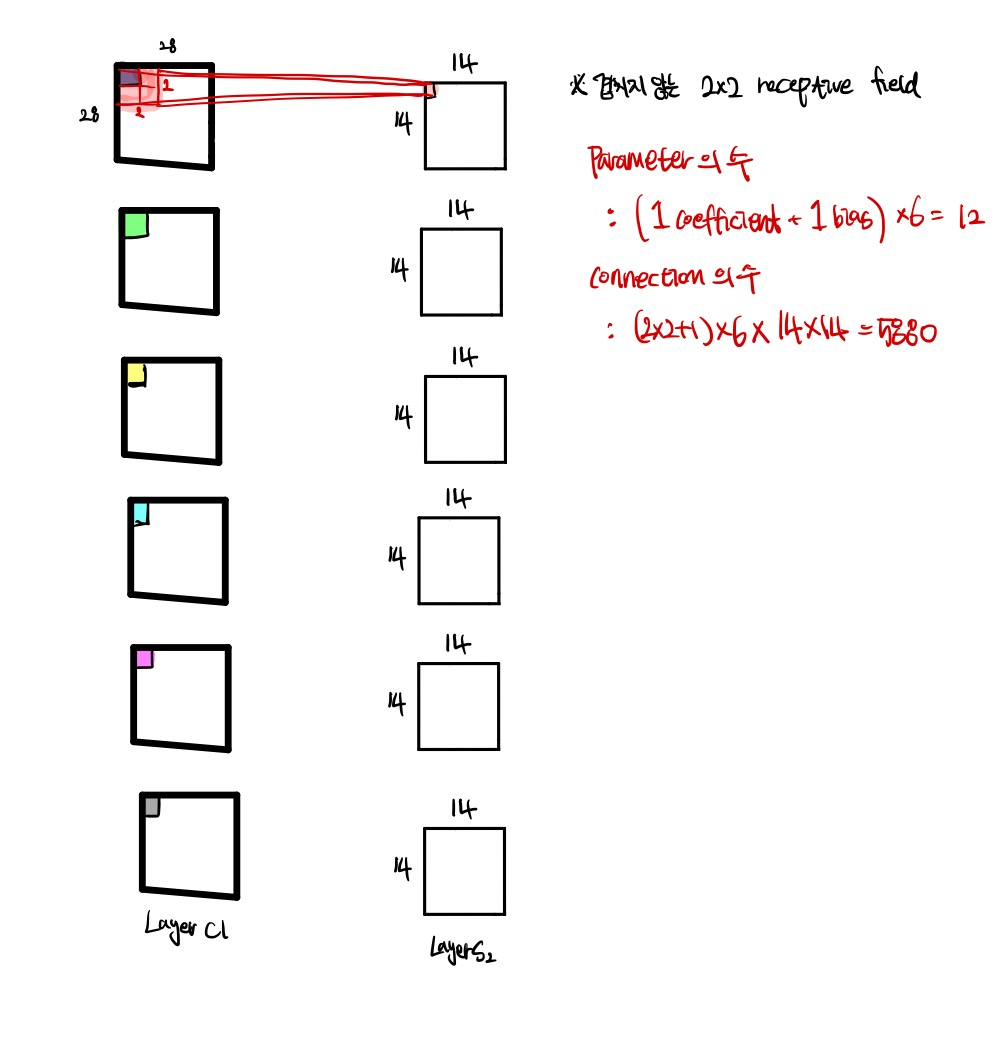
(4) Layer C3 ( Convolutional Layer)


Layer C3은 또 다시 convolutional layer이다. 16개의 feature map(왜 16개인지는 곧 나온다)의 unit은 S2의 5*5 데이터와 연결되어 있다.
이제부터 C3의 핵심인데, 먼저 표 하나만 보고 넘어가자.
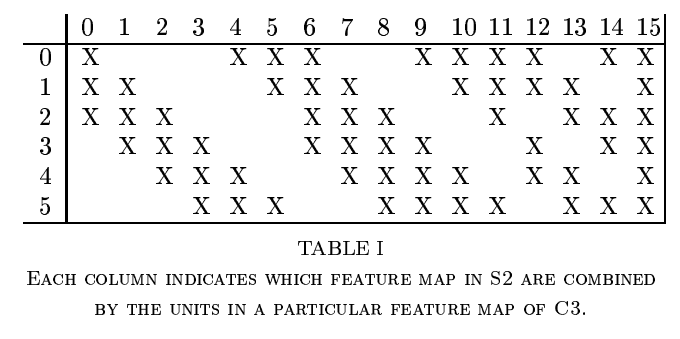
표를 이해 해보면, 각각의 열은 S2에서의 어떠한 feature map들이 C3의 어떠한 feature map과 연결되어 있는지 알 수 있다고 한다. 예를 들어, C3의 2번째 feature map은 S2의 2번째, 3번째, 4번째 feature map과 연결되어 있다.
왜 S2의 모든 feature map을 C3의 feature map에 연결하지 않는 것일까? 이유는 두가지이다.
첫번째, 불완전한 연결은 connection의 수가 reasonable한 bound를 유지할 수 있게 해준다.
더 중요한 두번째 이유로, 이러한 연결은 network의 symmetry를 깨준다.
Table을 보면, C3에서의 6번째 feature map의 생성까지는 S2의 연속인 3개의 feature map을 이용하고, 다음의 6개의 feature map의 생성은 S2의 연속인 4개의 feature map을, 그 다음 3개는 S2의 불연속적인 4개의 feature map을, 마지막은 S2의 전체적인 feature map을 사용함을 알 수 있다.
Layer C3은 1,516 개의 학습 가능한 parameter을 갖고 있으며, connection은 151,600개이다.
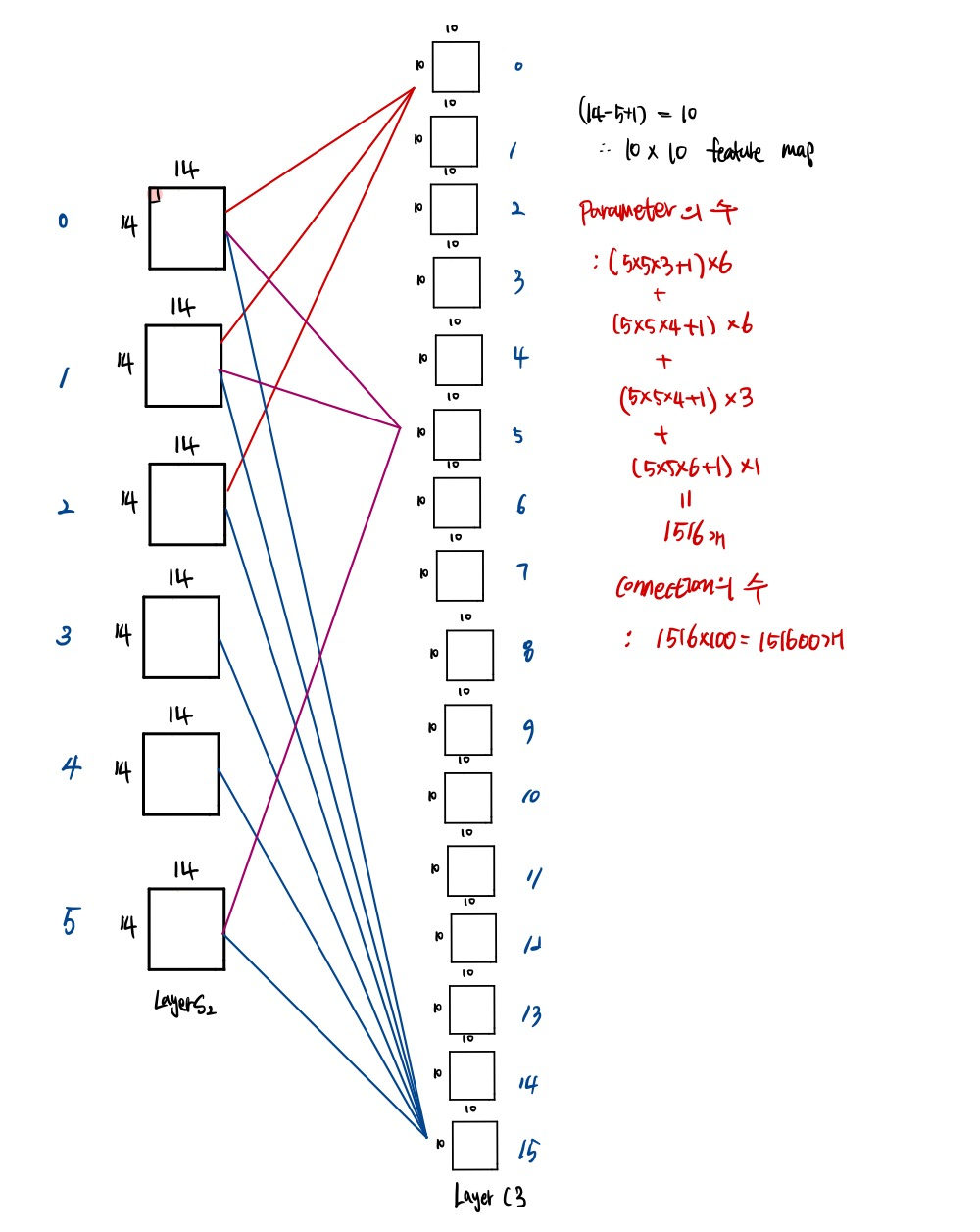
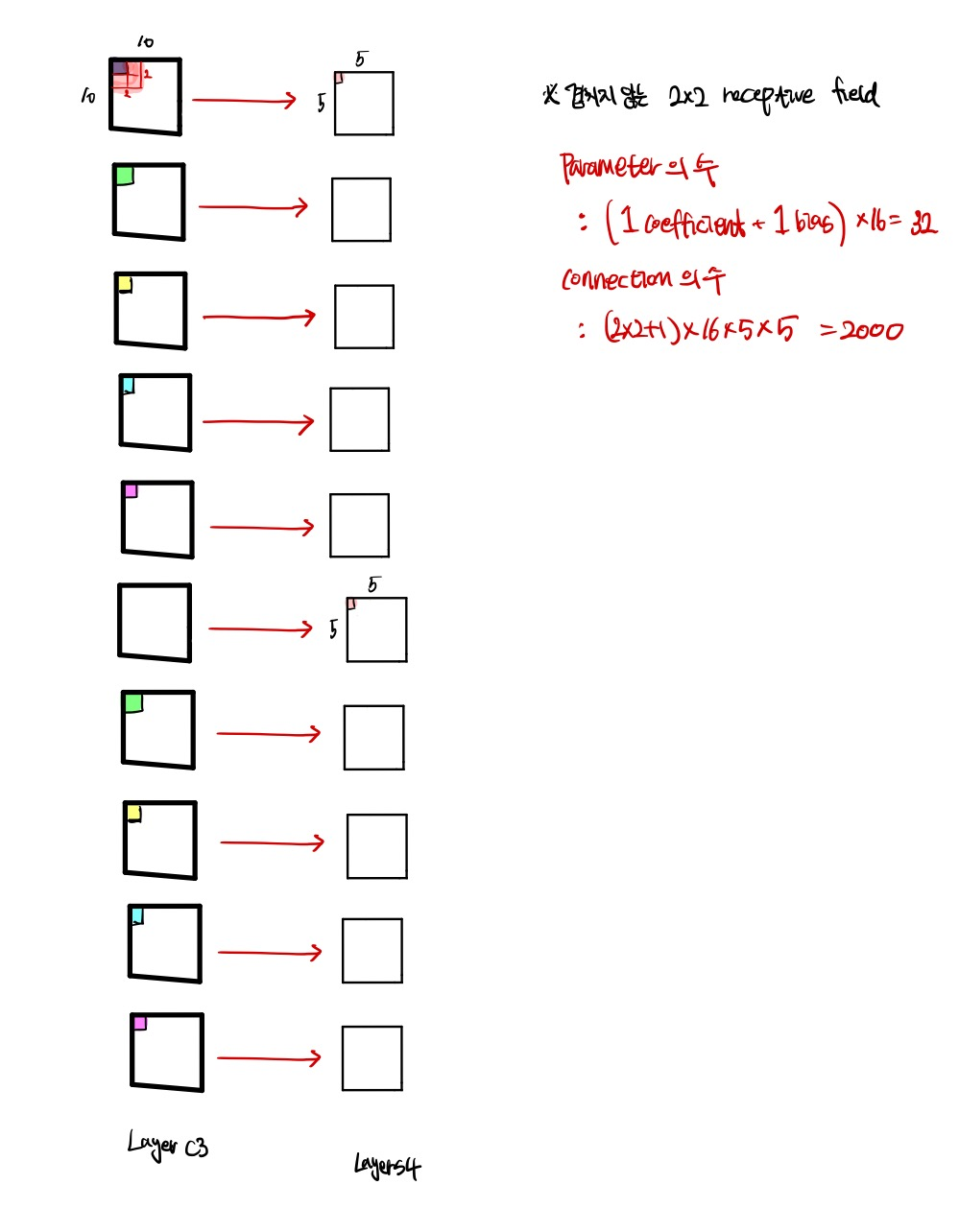
(5) Layer S4 (Subsampling Layer)

Layer S4는 5*5 사이즈 16개의 feature map을 갖는 sub-sampling layer이다. feature map의 각각의 유닛은 C3의 2*2 데이터와 연결되어 있으며, S4에는 32개의 학습가능한 parameter들과 2,000개의 connection이 존재한다.
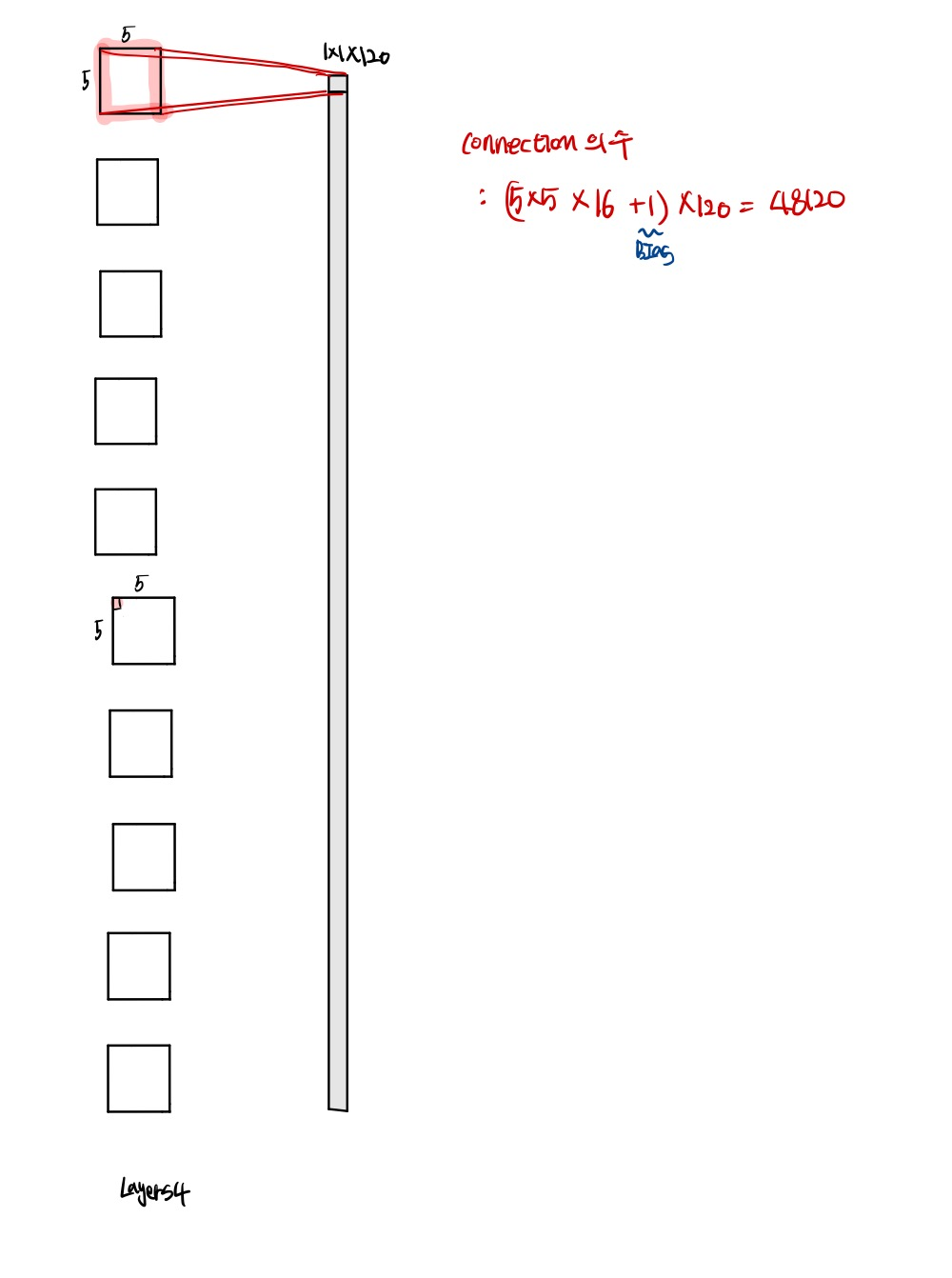
(6) Layer C5 ( Convolutional Layer)

Layer C5은 120개의 feature map을 갖는 convolutional layer로, 각각의 유닛은 S4의 16개 feature map의 모든 5*5 데이터와 연결되어 있다. S4의 feature map의 size가 5*5 였으므로, convolutin의 결과로 나오는 C5의 feature map의 size는 1*1이 된다. C5는 fully-connected layer라고 불리지 않는데, 왜냐하면 LeNet-5의 input이 더 컸다면, feature map의 차원은 1*1보다 컸을 것이기 때문이다. C5에는 48,120개의 학습 가능한 연결이 존재한다.
(7) Layer F6 (Fully-Connected Layer)

Layer F6는 84개의 유닛을 갖고 있고, C5와 fully connected 되어있다. (왜 84개의 유닛을 갖고 있는지는 output layer의 디자인에서 살펴보자)
(8) Output Layer
Output Layer는 10개의 Euclidean radial basis function(RBF)로 구성되어 있다. RBF는 Layer F6의 84개의 인풋을 받아 최종적으로 이미지가 속한 class를 알려준다. 이 10개의 출력에서, 각각의 출력은 이미지가 그 class에 속할 확률이다.
84개의 인풋을 받는 이유는 ASCII set을 해석하기 위하여 적합한 형태로 결과가 나와주길 원했기 때문이라고 한다. (사실 이해가 되지 않는다)
주어진 input pattern에 대하여, Loss function은 MSE를 사용하며, 학습할 때에는 역전파를 이용한다.
오늘은 LeNet-5가 등장한 논문에서 시대 배경과 LeNet-5의 구조를 알아보았다.
곧 LeNet-5 구현을 직접 해보고, 포스팅 하도록 하겠다.



