
Logical Scribbles
[논문 리뷰] Very Deep Convolutional Networks For Large-Scale Image Recognition (VGG) - 실험 결과 본문
[논문 리뷰] Very Deep Convolutional Networks For Large-Scale Image Recognition (VGG) - 실험 결과
KimJake 2023. 11. 13. 13:13지난 포스팅에 이어서 VGG모델의 실험 결과를 살펴보도록 하자.
Dataset
ILSVRC-2012 dataset(이미지넷)을 사용하였다. 이 데이터셋은 1000개의 class를 포함하고 있고, 3종류로 split 되어 있다. (Training data, Validation data, Testing data)
이러한 데이터셋의 1000개의 class를 classification 하는 것에 있어 performance의 측정 방식은 두가지이다.
- Top-1 Error : 예측이 잘못된 이미지의 비율
- Top-5 Error : 예측된 top-5 class에 정답이 없는 이미지의 비율
ILSVRC-2012에서는 두번째 측정 방식을 주요 평가 지표로 사용하였다고 한다. 또한, 이 실험에서는 이미지넷 데이터셋의 Validation 데이터를 Test 데이터로써 사용하였다고 한다.
1. Single scale evaluation
지난 포스팅에서 언급했던 single scale training과 마찬가지로, Test sclale Q를 고정시켜 테스트하는 방식이다. Q는 두가지 방식으로 설정되었는데, training 과정에서 사용하였던 Training scale S와 같은 Q를 사용하는 방식과 jittered S의 평균값을 Q로 사용하는 방법 두가지이다. 이 방식으로 test를 진행하였을 때의 결과는 다음 표와 같다.

이 실험으로 저자가 알아낸 것은 대표적으로 3가지이다.
- AlexNet에서 사용되었던 Local Response Normalization (LRN)을 적용한 A-LRN이 LRN을 사용하지 않은 모델(A)에 비하여 유의미한 성능 차이를 보이지 않았다.
- ConvNet의 깊이가 깊어질수록, classification error가 감소되는 경향을 보인다. 또한 같은 깊이를 갖더라도 1*1 Conv layer를 사용한 모델 C가 3*3 Conv layer를 사용한 모델 D보다 성능이 안좋았다. 이것은 추가적인 비선형성이 도움이 되긴하지만 (B보다 C가 성능이 우수함), ConvFilter를 이용하여 '공간적인 맥락'을 파악하는 것이 더 중요하다는 것을 암시한다. 또한 5*5 Conv 필터를 사용하는 것보다 3*3 Conv 필터 2개를 사용하는 것이 더 효과적이다.
- Training 과정에서 scale jittering은 확실히 성능 향상에 도움이 된다. (비록 test scale이 고정 되어있어도)
2. Multi scale evaluation
이번에는 Test scale Q를 다양하게 설정하여 평가해보자. training scale과 test scale 사이의 큰 차이는 오히려 성능의 drop의 요인일 수 있기 때문에, 저자는 1개의 fix된 training scale S에 대해 3가지의 Q를 세팅하여 test하였다. 세팅된 Q는 각각 S-32, S, S+32이다. training과정에서 scale jittering이 있는 경우, Q를 minimum jittering scale, maximum jittering scale, 그리고 minimum과 maximum의 평균을 사용하였다.

위의 Single test scale performance 표와 비교했을 때, 확실히 성능 향상이 있음을 알 수 있다. 저자는 E모델을 test데이터셋에 적용하였을 때 7.3%의 Top-5 error를 얻을 수 있었다고 한다.
3. Multi crop evaluation
Dense evaluation 과 multi-crop evaluation을 따로따로 진행하고, 섞어서도 진행 해보았는데 섞어서 평가하는 방식이 더 정확한 결과를 냈다고 한다.
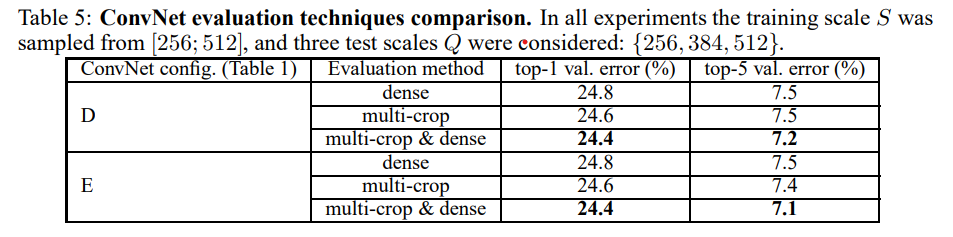
4. ConvNet Fusion
앙상블 기법을 적용하여 실험하였을 때의 결과를 소개하고 있다. 모델 7개를 앙상블하여 ILSVRC에 제출하였고, 최종적으로 7.3%의 error로 대회는 마무리하였다. 대회 이후 추가적으로 모델의 error를 6.8%까지 낮추었다고 한다.

다음 글에서는 이 VGG를 직접 구현해보도록 하자!



