
Logical Scribbles
[논문 구현] AlexNet 구현하기 (By Colab, PyTorch) 본문
이번에는 이 AlexNet의 구조에 대해 빠르게 복습한 후 구현을 해보도록 하자. 구현하는데 있어서 두가지 정도의 어려움이 있었는데, 이후 설명하도록 하겠다.

AlexNet에는 5개의 Convolutional layer와 3개의 Fully-connected layer가 존재한다.
AlexNet에 입력 되는 이미지의 사이즈는 227 x 227 x 3 이다. 위의 그림에는 224로 되어 있는데 잘못된 것이다. (저자가 이후에 227이 맞다고 정정하였다고 한다.)
이미지의 전처리 과정을 살펴보면 데이터셋의 이미지의 사이즈를 먼저 256*256 사이즈로 crop 한 뒤, 227*227사이즈로 random crop 한다. 이후 horizontal reflection을 적용해야하고, PCA를 적용해야 한다. 이 과정에서 어려움을 겪었다. PCA 처리를 하는 class를 직접 만들어야 했기 때문이다. 자세한 설명은 뒤에 나온다.
AlexNet의 구조가 잘 정리되어 있는 표를 찾았다. 위 표를 보고 모델을 잘 설계하면 되겠다.
AlexNet의 구현을 위해서 정의해야하는 것들은 다음과 같다.
- 모델의 정확도 측정 함수
- 손실 plotting 함수
- Train 함수
- Validate 함수
- Training_loop 함수
- Class PCAonIMG
- Class AlexNet
- Hyperparameters
위의 함수 목록에서 1번, 2번, 3번, 4번, 5번 함수는 ReNet-5와 VGG16의 구현에서 사용한 함수들을 그대로 사용할 것이다. 하지만 AlexNet의 이미지 전처리 과정과 hyperparameter 그리고 모델 구조는 이전의 구현들과 다르기 때문에 새롭게 코드를 짜 보았다.
1. 모델의 정확도 측정 함수
# 모델의 정확도를 얻는 함수를 먼저 정의하자
def get_accuracy(model, data_loader, device) :
correct_pred = 0
n = 0
with torch.no_grad() :
model.eval() #batch nomalization, drop out과 같은거 없이! 모델이 평가모드로 전환
for X, y_true in data_loader : #데이터 셋에 있는 인풋
X = X.to(device)
y_true = y_true.to(device)
_, y_prob = model(X) #y_prob은 후에 나올 LeNet-5 모델에서 소프트맥스 함수를 통과한 클래스 확률
_, predicted_labels = torch.max(y_prob,1) #torch.max(y_prob,1) = 열 중에서 가장 높은 값을 뽑아준다. 그럼 그게 예측 라벨이 되겠죠?
n += y_true.size(0)
correct_pred += (predicted_labels == y_true).sum()
return correct_pred.float() / n # 정확히 맞춘것 / 총 개수
2. 손실 plotting 함수
def plot_loss(train_loss, val_loss) :
plt.style.use('grayscale')
train_loss = np.array(train_loss)
val_loss = np.array(val_loss)
fig , ax = plt.subplots(1,1,figsize = (8,4.5))
ax.plot(train_loss, color = 'green' , label = 'Training Loss')
ax.plot(val_loss, color = 'red' , label = 'Validation Loss')
ax.set(title = 'Loss Over Epochs' , xlabel = 'EPOCH' , ylabel = 'LOSS')
ax.legend()
fig.show()
plt.style.use('default')
3. Train 함수
def train(train_loader, model, criterion, optimizer, device) :
model.train() #모델을 학습 모드로 설정
running_loss = 0 # 초기값 0으로 설정
for X, y_true in train_loader:
optimizer.zero_grad() #역전파시 효과적으로 학습되기 위해 설정 매번 세팅되어야함
X = X.to(device)
y_true = y_true.to(device)
y_hat, _ = model(X)
loss = criterion(y_hat,y_true) #loss를 구함
running_loss += loss.item() * X.size(0) #사이즈를 곱해줘서 전체적인 running loss를 구함
loss.backward() #역전파
optimizer.step() #Gradient descent
epoch_loss = running_loss / len(train_loader.dataset)
return model , optimizer, epoch_loss
4. Validate 함수
def validate(valid_loader, model, criterion, device):
model.eval()
running_loss = 0
for X, y_true in valid_loader:
X = X.to(device)
y_true = y_true.to(device)
# 순전파와 손실 기록하기
y_hat, _ = model(X) #소프트 맥스 당하기 전 !
loss = criterion(y_hat, y_true)
running_loss += loss.item() * X.size(0)
epoch_loss = running_loss / len(valid_loader.dataset)
return model, epoch_loss
5. Training_loop 함수
def training_loop(model, criterion, optimizer, train_loader, valid_loader, epochs, device, print_every=1):
# metrics를 저장하기 위한 객체 설정
best_loss = 1e10
train_losses = []
valid_losses = []
# model 학습하기
for epoch in range(0, epochs):
# training
model, optimizer, train_loss = train(train_loader, model, criterion, optimizer, device)
train_losses.append(train_loss)
# validation
with torch.no_grad():
model, valid_loss = validate(valid_loader, model, criterion, device)
valid_losses.append(valid_loss)
if epoch % print_every == (print_every - 1):
train_acc = get_accuracy(model, train_loader, device=device)
valid_acc = get_accuracy(model, valid_loader, device=device)
print(datetime.now(timezone('Asia/Seoul')).time().replace(microsecond=0),'--- ',
f'Epoch: {epoch}\t'
f'Train loss: {train_loss:.4f}\t'
f'Valid loss: {valid_loss:.4f}\t'
f'Train accuracy: {100 * train_acc:.2f}\t'
f'Valid accuracy: {100 * valid_acc:.2f}')
plot_loss(train_losses, valid_losses)
return model, optimizer, (train_losses, valid_losses)
여기까지는 LeNet-5와 VGG16의 구현에서 사용했던 함수들이다. 이제 필요한 데이터셋을 불러오자.
6. 데이터셋 불러오고 확인하기
VGG16의 구현에서와 마찬가지로, 이미지넷의 데이터셋을 이용하면 시간이 너무 오래걸릴 것 같아 STL10 데이터셋을 사용하였다. STL10 데이터셋의 클래스 개수는 10개이고, training 데이터셋은 5000개, validation 데이터셋은 8000개이다.
from google.colab import drive
drive.mount('AlexNet')
# specify a data path VGG와 같은 데이터셋 사용
path2data = '/content/AlexNet/MyDrive/data'
# if not exists the path, make the directory
if not os.path.exists(path2data):
os.mkdir(path2data)
# load dataset
train_ds = datasets.STL10(path2data, split='train', download=True, transform=transforms.ToTensor())
val_ds = datasets.STL10(path2data, split='test', download=True, transform=transforms.ToTensor())
plt.imshow(train_ds.data[10].T) #대충 어떤 이미지가 있나 봅시다.
print(len(train_ds)) # train data의 개수
print(len(val_ds)) # test data의 개수
train_ds[0][0].shape
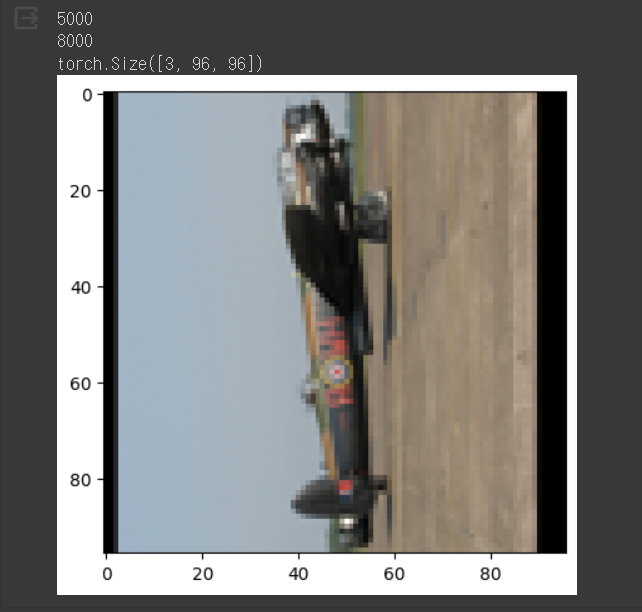
위 사진이 위 코드의 출력 결과이다. 확인해보니 STL10 데이터셋의 이미지 크기는 3*96*96임을 확인할 수 있다.
7. class PCAonIMG 생성하기
본 논문에서는 데이터 증강을 통한 오버피팅 방지를 위하여 이미지 전처리 과정에서 한개의 과정을 추가하였다.
픽셀의 RGB value에 PCA를 적용 한 후 주성분 요소들의 곱을 training 이미지에 더한 것이다. 수식으로 보면 다음과 같다.
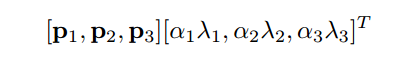
벡터 P와 감마들은 3*3 RGB픽셀의 공분산 행렬의 고유벡터와 고유값이다. 알파는 저자가 설정한 hyperparameter로, 평균이 0이고 표준 편차가 0.1인 가우시안 분포에서 선택한 random variable이다.
이 부분을 구현하는 것이 나에게는 어려웠다.. 인터넷을 많이 뒤져보고 찾아보았다. 그런데 한가지 문제점이 있었다.
내가 사용한 STL10 데이터셋의 RGB픽셀값에 대한 고유값과 고유벡터를 계산하는 것이 너무 오래 걸렸기 때문이다. 따라서 이미지넷의 고유값과 고유벡터를 찾아내어 이들의 값으로 실험을 진행했다. (이 부분에서 오차가 어느정도 있었을 것이다.)
Does anyone have the eigenvalue and eigenvectors for Alexnet's PCA noise from the imagenet dataset?
Does anyone have the eigenvalue and eigenvectors for Alexnet's PCA noise from the imagenet dataset? The imagenet dataset has 12million images and my computer is unable to calculate PCA for such a ...
stackoverflow.com
from PIL import Image
class PCAonIMG(object):
def __init__(self,
alphastd=0.1,
eigval=np.array([55.46, 4.794, 1.148]),
eigvec=np.array([[-0.5675, 0.7192, 0.4009],
[-0.5808, -0.0045, -0.8140],
[-0.5836, -0.6948, 0.4203],])
):
self.alphastd = alphastd
self.eigval = eigval
self.eigvec = eigvec
self.set_alpha()
def __call__(self, img):
# 1. pil to numpy
img_np = np.array(img) # [H, W, C]
offset = np.dot(self.eigvec * self.alpha, self.eigval)
img_np = img_np + offset
ret = Image.fromarray(np.uint8(img_np))
return ret
def set_alpha(self, ):
# change per each epoch
self.alpha = np.random.normal(0, self.alphastd, size=(3,))
8. 이미지 전처리 하기
이제 transforms를 정의하자.
# transforms 정의하기 잘 따라해 보자!!
transforms_set = transforms.Compose([transforms.Resize((256,256)),transforms.RandomCrop((227,227)),
transforms.RandomHorizontalFlip(0.5),PCAonIMG(),transforms.ToTensor()
])
전처리된 이미지와 원본 이미지를 비교하는 코드를 짜서 확인해 보았다. 이 과정에서 전처리도 진행된다.
sample_idx = 0
original_sample, _ = train_ds[sample_idx]
sample_idx = 0
original_sample, _ = train_ds[sample_idx]
train_ds.transform = transforms_set
val_ds.transform = transforms_set
transformed_sample, _ = train_ds[sample_idx]
# 원본 이미지와 변환된 이미지 비교
plt.subplot(1, 2, 1)
plt.imshow(original_sample.T)
plt.title('Original Image')
plt.subplot(1, 2, 2)
plt.imshow(transformed_sample.T)
plt.title('Transformed Image')
plt.show()

흠.. 사이즈와 horizontal flip은 적용된 것 같은데 PCA는 적용이 된건지 모르겠다. 이미지넷 데이터셋의 주성분을 사용해서 그런가?
9. AlexNet class 만들기
이제 AlexNet class를 만들어보자. 앞의 구조 그림들과 표를 잘 보고 따라오면 된다. 본 논문에서 dropout과 가중치 초기화를 사용해주었기 때문에 최대한 이 부분을 따라해 보았다.
pytorch에 Local Response Normalization이 있는지 몰랐는데 이번에 알게 되었다. parameter들은 논문을 따라주었다.
class AlexNet(nn.Module):
def __init__(self, n_classes):
super(AlexNet, self).__init__()
self.feature_extractor = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=96, kernel_size=11, stride=4,padding=0), #Bias default
nn.ReLU(),
nn.LocalResponseNorm(size=5, alpha=0.0001, beta=0.75, k=2),
nn.MaxPool2d(kernel_size=3, stride = 2),
nn.Conv2d(in_channels=96, out_channels=256, kernel_size=5,stride=1,padding=2),
nn.ReLU(),
nn.LocalResponseNorm(size=5, alpha=0.0001, beta=0.75, k=2),
nn.MaxPool2d(kernel_size=3, stride = 2), # default stride = kernel_size
nn.Conv2d(in_channels=256, out_channels=384, kernel_size=3, stride=1,padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=384, out_channels=384, kernel_size=3, stride=1,padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, stride=1,padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride = 2)
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(in_features = 256*6*6, out_features=4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(in_features=4096, out_features=4096),
nn.ReLU(),
nn.Linear(in_features=4096, out_features=n_classes)
)
# bias, weight 초기화
def init_bias_weights(self):
for layer in self.feature_extractor:
if isinstance(layer, nn.Conv2d):
nn.init.normal_(layer.weight, mean=0, std=0.01) # weight 초기화
nn.init.constant_(layer.bias, 0) # bias 초기화
# conv 2, 4, 5는 bias 1로 초기화
nn.init.constant_(self.net[4].bias, 1)
nn.init.constant_(self.net[10].bias, 1)
nn.init.constant_(self.net[12].bias, 1)
def forward(self, x):
x = self.feature_extractor(x)
x = torch.flatten(x, 1) # 1차원으로 쫙펴준다
logits = self.classifier(x) # classifier에 통과시켜준다
probs = F.softmax(logits, dim=1) # 나온 10개의 값들을 softmax로 확률 구해준다.
return logits, probs
10. Hyperparameters
이 부분도 learning rate을 제외하고는 최대한 논문을 따라주었다.
Random_seed = 42 #그냥 정하는 것
Learning_rate = 0.0001 # 학습률. 논문에서는 0.01로 시작하여 감소시키지만 VGG 모델 구현에서의 경험으로 우선 0.0001로 해보자
Batch_size = 128 # batch size. 이 단위로 학습이 된다. 논문에서 제시된 128 로 설정해보자.
N_epochs = 50 # epoch 횟수 전체 데이터가 50번 학습된다는 뜻. VGG에서도 50번정도로 설정했으니 비슷하게 해보자
Img_size = 256 # 이후 전처리 된 227*227 RGB 이미지가 모델에 들어갈 것이다.
N_classes = 10 # 데이터셋의 10개의 output class가 있다. 1000개는 시간이 너무 오래 걸릴 듯하다..
11. 학습 !
이제 학습시켜보자! 그 전에 먼저 optimizer와 사용할 loss를 정하자. 논문에서는 SGD를 사용하였지만 나는 Adam을 사용하였다.
torch.manual_seed(Random_seed)
model = AlexNet(N_classes).to(DEVICE)
optimizer = torch.optim.Adam(model.parameters(), lr=Learning_rate,weight_decay=0.0005)
criterion = nn.CrossEntropyLoss()
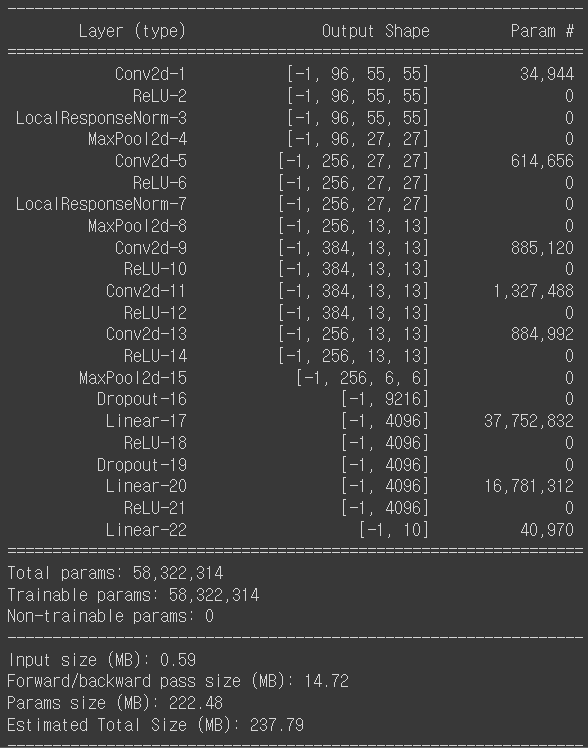
import torchsummary
torchsummary.summary(model,(3,227,227))
model, optimizer, _ = training_loop(model, criterion, optimizer, train_loader,
valid_loader, N_epochs, DEVICE)
이제 학습을 시켜보자. 50 Epoch만큼 데이터가 학습될 것이다. 구글 Colab 환경에서 50 Epoch에 약 1시간 30분 정도 소요된 것 같다.
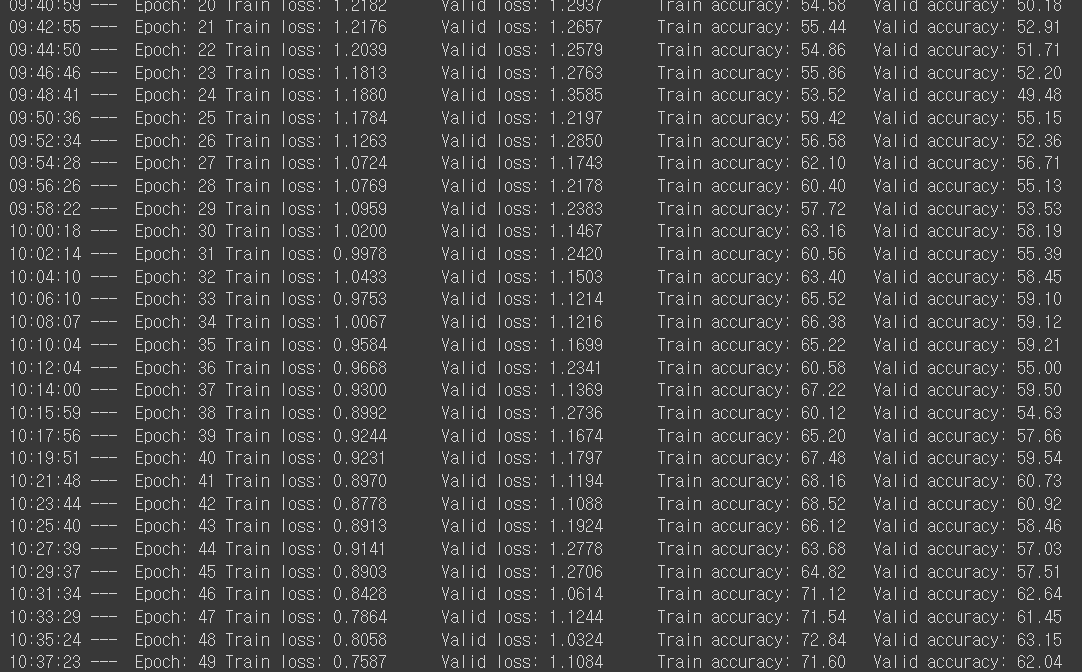
Train accuracy와 valid accuracy가 만족스럽지는 않다. 아마 epoch를 더 늘리면 정확도가 올라갈 것 같다. 추후에 epoch를 150번정도로 다시 학습 시켜봐야겠다.
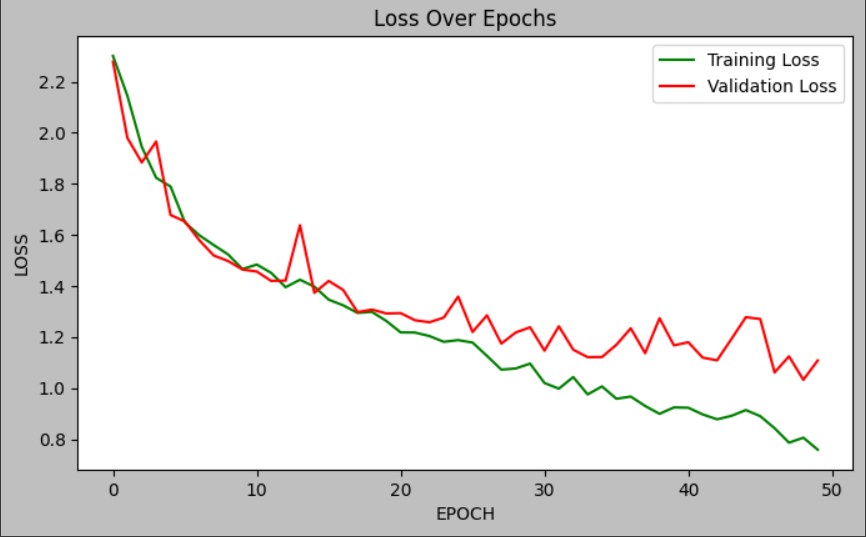
AlexNet 구현 끝!
참고: https://csm-kr.tistory.com/20 , https://roytravel.tistory.com/336
'Papers > 논문 구현' 카테고리의 다른 글
| [논문 구현] Visual Prompt Tuning 구현해보기 (0) | 2023.12.30 |
|---|---|
| [논문 구현] Vision Transformer (0) | 2023.12.30 |
| [논문 구현] 트랜스포머(Transformer) 구현하기 (2) | 2023.12.01 |
| [논문 구현] VGG16 구현하기 (By Colab, PyTorch) (2) | 2023.11.14 |
| [논문 구현] LeNet-5 구현하기 (By Colab, PyTorch) (1) | 2023.11.12 |


