
Logical Scribbles
[논문 구현] 트랜스포머(Transformer) 구현하기 본문
이번 포스팅에서는 트랜스포머를 구현해보자. 트랜스포머가 소개된 논문은 "Attention Is All You Need"이다. 구조에 대한 설명은 아래 글에서 확인할 수 있다.
[논문 리뷰] Attention Is All You Need (Transformer)
오늘은 대망의 'Attention Is All You Need' 논문에 대해서 리뷰해보겠다. Attention Is All You NeedThe dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration.
stydy-sturdy.tistory.com
다시 한번 전체적인 구조를 살펴보자.
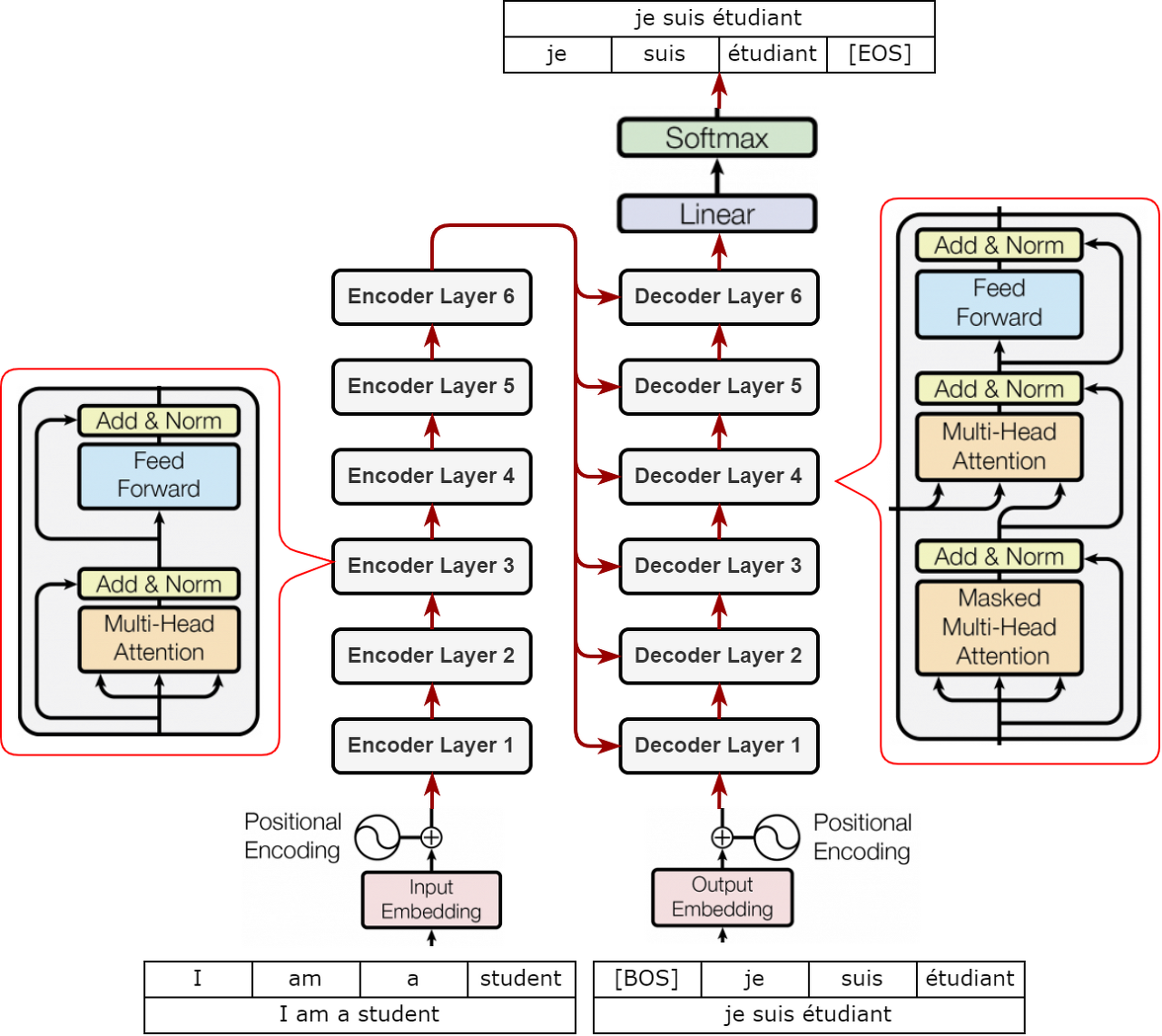
위 그림에서 인코더/디코더 레이어가 6개 존재하고 인코더 레이어 안에는 2개의 서브 레이어, 디코더 안에는 3개의 서브 레이어가 존재한다. 하지만 서브 레이어를 잘 살펴보면 크게 Feed Forward와 Multi-head attention 2개의 레이어로 구성되어 있어 이에 대한 class를 만들어주면 될 것으로 보인다. 추가적으로 잔차 연결에 대한 class를 만들어야하고, layer nomalization class도 만들어줘야 한다. 또한 문장 안에서 단어의 위치 정보를 담고 있는 positional encoding class도 필요해 보인다.
이제 하나하나 만들어보자. 클래스를 여러개 만든 다음, 1개의 트랜스포머 클래스 안에서 조립해 줄 것이다.
1. Input Embeddings
class InputEmbeddings(nn.Module) :
def __init__(self, d_model : int , vocab_size : int) :
super().__init__()
self.d_model = d_model
self.vocab_size = vocab_size
self.embedding = nn.Embedding(vocab_size , d_model)
def forward(self, x) :
return self.embedding(x) * math.sqrt(self.d_model)
이 부분에서 임베딩 레이어에 입력되는 텐서를 임베딩 벡터로 바꾸어주는 역할을 수행한다. 파라미터로 d_model과 vocab_size가 필요하다. d_model은 임베딩 차원으로, 논문에서는 512로 설정했다. vocab_size는 단어 집합의 크기이다. 또한 논문에서 가중치에 d_model의 루트값을 곱해준다고 제시되었기 때문에, 이 부분도 구현을 해주었다.
2. Positional Encoding
class PositionalEncoding(nn.Module) :
def __init__(self, d_model : int, seq_len : int, dropout : float) :
super().__init__()
self.d_model = d_model
self.seq_len = seq_len
self.dropout = nn.Dropout(dropout)
# (seq_len , d_model) 로 이루어진 행렬을 만들자.
pe = torch.zeros(seq_len , d_model)
# (seq_len) 길이의 벡터를 만들자.
position = torch.arrange(0,seq_len , dtype = torch.float).unsqueeze(1) #(seq_len,1)의 벡터를 만든다
div_term = torch.exp(torch.arrange(0 , d_model , 2).float() * (-math.log(10000.0) / d_model))
# 짝수 포지션에 사인 함수를 적용한다.
pe[:, 0::2] = torch.sin(position * div_term)
# 홀수에는 코사인!
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0) # (1, seq_len, d_model)
self.register_buffer('pe' , pe)
def forward(self,x) :
x = x + (self.pe[:, :x.shape[1],:]).requires_grad_(False)
return self.dropout(x)

위에서 소개하는대로 positional encoding 클래스를 구현하면 된다. 간략하게 말해서 어떤 단어에 대해 짝수 번째 차원에는 사인 함수를 적용하고, 홀수 번째에는 코사인 함수를 적용한다. position은 단어의 위치이다.
div_term이 약간 헷갈릴 수 있는데 수식을 잘 확인해보면 논문에서 제시된 식임을 알 수 있을 것이다. 또한 코드 중 register_buffer는 위치 인코딩을 나타내는 pe 텐서를 모델의 상태로 등록하고, 학습 중에 업데이트 되지 않도록 한다.
3. Layer Nomalization
class LayerNomalization(nn.Module) :
def __init__(self, eps : float = 10**(-6)) -> None :
super().__init__()
self.eps = eps
self.alpha = nn.Parameter(torch.ones(1)) # 곱해질것
self.bias = nn.Parameter(torch.zeros(1)) #더해지는 것
def forward(self,x) :
mean = x.mean(dim = -1 , keepdim = True)
std = x.std(dim = -1, keepdim= True)
return self.alpha * (x - mean) / (std + self.eps) + self.bias
이 부분은 쉽다.
4. Feed Forward Block
class FeedForwardBlock(nn.Module) :
def __init__(self, d_model : int, d_ff : int , dropout : float) -> None :
super().__init__()
self.linear_1 = nn.Linear(d_model, d_ff) #W1 and B1
self.dropout = nn.Dropout(dropout) #dropout
self.linear_2 = nn.Linear(d_ff, d_model) #W2 and B2
def forward(self,x) :
# (Batch, seq_len, d_model) --> (Batch, seq_len , d_ff) --> (Batch, seq_len, d_model)
return self.linear_2(self.dropout(torch.relu(self.linear_1(x))))
Feed Forward에 대한 수식을 다시 확인해보자.
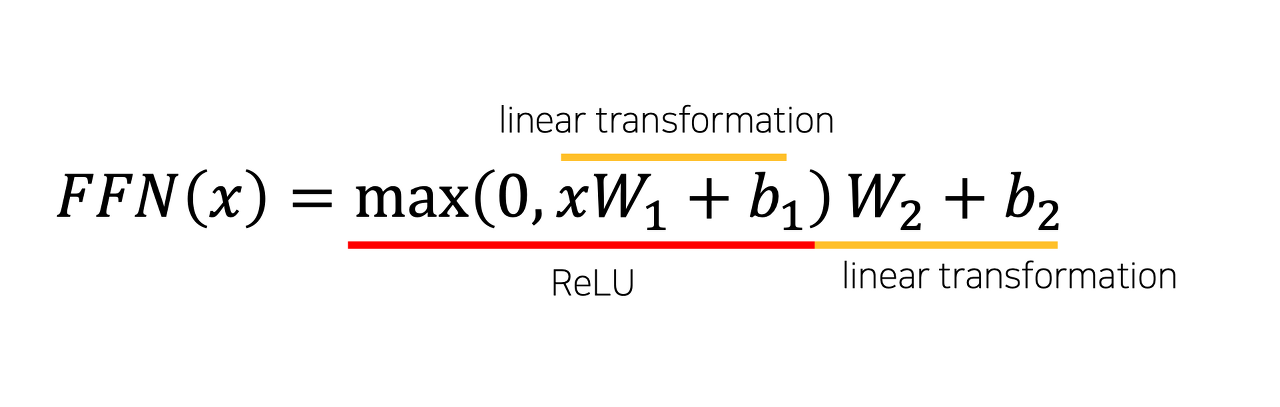
Linear 층이 두개가 필요함을 알 수 있다. 각각 linear_1, linear_2 라는 코드로 구현하였다. 논문에서는 d_ff = 2024로 제시하고 있다.
5. Multi-Head Attention Block
class MultiHeadAttentionBlock(nn.Module) :
def __init__(self,d_model:int ,h:int, dropout:float) -> None :
super().__init__()
self.d_model = d_model
self.h = h
assert d_model % h == 0, "d_model is not divisible by h"
self.d_k = d_model // h
self.w_q = nn.Linear(d_model , d_model) #Wq
self.w_k = nn.Linear(d_model , d_model) #Wk
self.w_v = nn.Linear(d_model , d_model) #Wv
self.w_o = nn.Linear(d_model , d_model) #Wo
self.dropout = nn.Dropout(dropout)
@staticmethod
def attention(query, key, value, mask ,dropout : nn.Dropout) :
d_k = query.shape[-1]
# (Batch, h, seq_len, d_k) --> (Batch ,h, seq_len , seq_len)
attention_scores = (query @ key.transpose(-2,-1)) / math.sqrt(d_k)
if mask is not None :
attention_scores.masked_fill(mask == 0 , -1e9)
attention_scores = attention_scores.softmax(dim = -1) # ( Batch , h, seq_len, seq_len)
if dropout is not None :
attention_scores = dropout(attention_scores)
return (attention_scores @ value ) , attention_scores
def forward(self,q,k,v,mask) :
query = self.w_q(q) #(Batch, seq_len, d_model) --> (Batch, seq_len, d_model)
key = self.w_k(k) #(Batch, seq_len, d_model) --> (Batch, seq_len, d_model)
value = self.w_v(v) #(Batch, seq_len, d_model) --> (Batch, seq_len, d_model)
#(Batch, seq_len, d_model) --> (Batch, seq_len, h, d_k) --> (Batch, h, seq_len, d_k)
query = query.view(query.shape[0] , query.shape[1] , self.h , self.d_k).transpose(1,2)
key = key.view(key.shape[0] , key.shape[1] , self.h , self.d_k).transpose(1,2)
value = value.view(value.shape[0] , value.shape[1] , self.h , self.d_k).transpose(1,2)
x, self.attention_scores = MultiHeadAttentionBlock.attention(query, key, value, mask , self.dropout)
# (Batch , h, seq_len, d_k) --> (Batch, seq_len, h, d_k) --> (Batch, seq_len, d_model)
x = x.transpose(1,2).contiguous().view(x.shape[0],-1,self.h * self.d_k)
return self.w_o(x)
나에게 이 부분이 가장 어려웠다. multi-head attention을 위해 h값이 필요하다. h는 head로, 논문에서는 8로 설정하였다.
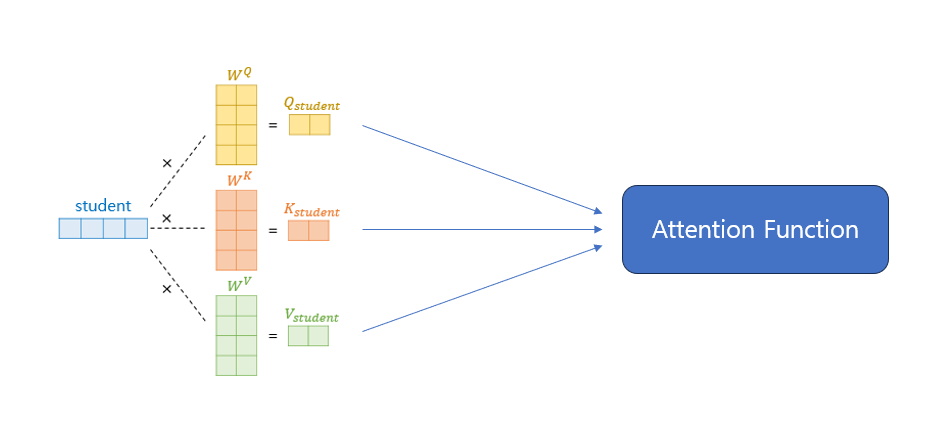
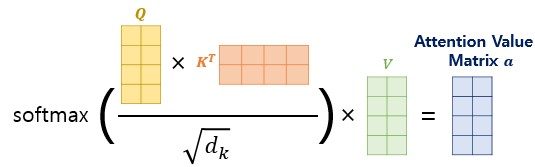
위의 그림을 보면 이해가 더 쉽다. 먼저 Wq,Wk,Wv를 정의해야 한다. 우선 모두 nn.linear(d_model, d_model)로 만들어주고, 어텐션 스코어 함수를 정의해준다. return 값으로는 두 개를 받는데, 어텐션 스코어에 벨류 값을 내적한 값과 어텐션 스코어 자체를 return 받는다. 중요한 것은 어텐션 스코어에 루트 d_k를 나눠줘야 한다는 것이다.
forward 과정에서는 쿼리, 키, 벨류의 차원을 잘 조절해주어 어텐션 스코어 함수에 넣어준다. 마지막에는 concatenate 하여 Wo에 넣어준다.
6. Residual Connection
class ResidualConnection(nn.Module) :
def __init__(self, dropout : float) -> None :
super().__init__()
self.dropout = nn.Dropout(dropout)
self.norm = LayerNomalization()
def forward(self, x, sublayer) :
return self.norm(x + self.dropout(sublayer(x)))
잔차연결과 nomalization에 관련된 클래스이다. 이에 대한 설명은 아래 논문에서 확인할 수 있다.

7. Encoder Block & Encoder
class EncoderBlock(nn.Module) :
def __init__(self, self_attention_block : MultiHeadAttentionBlock , feed_forward_block : FeedForwardBlock, dropout : float) -> None :
super().__init__()
self.self_attention_block = self_attention_block
self.feed_forward_block = feed_forward_block
self.residual_connections = nn.ModuleList([ResidualConnection(dropout) for _ in range(2)])
def forward(self,x, src_mask) :
x = self.residual_connection[0](x, lambda x: self.self_attention_block(x,x,x,src_mask))
x = self.residual_connection[1](x, self.feed_forward_block)
return x
class Encoder(nn.Module) :
def __init__(self, layers : nn.ModuleList) -> None :
super().__init__()
self.layers = layers
def forward(self,x,mask) :
for layer in self.layers :
x= layer(x,mask)
return self.x
이제 한개의 인코더 블럭을 만들고 전체적인 인코더를 만드는 클래스를 만든다.
코드 중 nn.ModuleList은 여러 개의 모듈을 리스트 형태로 관리하는 클래스이다. 주로 신경망 모델에서 일련의 서로 다른 모듈들을 리스트로 묶어서 사용할 때 활용된다. 해당 클래스는 forward 에서 입력 x에 대해 잔차 연결을 수행하는데, 첫번째 잔차 연결은 self-attention 블럭을 통과한 아웃풋에 대해 수행되고 두번째 잔차 연결은 feed forward block을 통과한 아웃풋에 대해 수행된다. self-attention block에서 쿼리, 키, 벨류 값이 모두 x임을 확인할 수 있다.
인코더 클래스에서는 여러 개의 인코더 블록을 쌓아 올린 구조이다.
8. Decoder Block & Decoder
class DecoderBlock(nn.Module) :
def __init__(self, self_attention_block : MultiHeadAttentionBlock , cross_attention_block : MultiHeadAttentionBlock,feed_forward_block : FeedForwardBlock, dropout : float) -> None :
super().__init__()
self.self_attention_block = self_attention_block
self.cross_attention_block = cross_attention_block
self.feed_forward_block = feed_forward_block
self.residual_connections = nn.ModuleList([ResidualConnection(dropout) for _ in range(3)])
def forward(self,x, encoder_output, src_mask , tgt_mask) :
x = self.residual_connection[0](x, lambda x: self.self_attention_block(x,x,x,tgt_mask))
x = self.residual_connection[1](x, lambda x: self.cross_attention_block(x,encoder_output,encoder_output, src_mask))
x = self.residual_connection[2](x, self.feed_forward_block)
return x
class Decoder(nn.Module) :
def __init__(self, layers : nn.ModuleList) -> None :
super().__init__()
self.layers = layers
def forward(self,x, encoder_output, src_mask , tgt_mask) :
for layer in self.layers :
x= layer(x, encoder_output, src_mask , tgt_mask)
return self.x
인코더 블럭과 인코더 클래스와 매우 유사하지만 cross attention block이 추가되었다. cross attention block에서는 키와 벨류를 인코더에서 받아온다.
9. Projection Layer
class ProjectionLayer(nn.Module) :
def __init__(self, d_model : int, vocab_size : int) -> None :
super().__init__()
self.proj = nn.Linear(d_model, vocab_size)
def forward(self,x) :
#(Batch, seq_len ,d_model) --> (Batch, seq_len, vocab_size)
return torch.log_softmax(self.proj(x),dim=-1)10. Transformer
class Transformer(nn.Module) :
def __init__(self, encoder : Encoder , decoder : Decoder,src_embed : InputEmbeddings , tgt_embed : InputEmbeddings, src_pos : PositionalEncoding, tgt_pos : PositionalEncoding, projection_layer : ProjectionLayer) -> None :
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.src_pos = src_pos
self.tgt_pos = tgt_pos
self.projection_layer = projection_layer
def encode(self, src, src_mask) :
src = self.src_embed(src)
src = self.src_pos(src)
return self.encoder(src,src_mask)
def decode(self, encoder_output, src_mask , tgt, tgt_mask) :
tgt = self.tgt_embed(tgt)
tgt = self.tgt_pos(tgt)
return self.decoder(tgt,encoder_output, src_mask, tgt_mask)
def project(self,x) :
return self.projection_layer(x)11. Build Transformer
def build_transformer(src_vocab_size :int, tgt_vocab_size : int, src_seq_len :int, tgt_seq_len : int, d_model : int = 512,N:int = 6, h: int = 8,dropout : float = 0.1 ,d_ff: int = 2048 ) -> Transformer :
src_embed = InputEmbeddings(d_model,src_vocab_size)
tgt_embed = InputEmbeddings(d_model,tgt_vocab_size)
src_pos = PositionalEncoding(d_model, src_seq_len, dropout)
tgt_pos = PositionalEncoding(d_model, tgt_seq_len, dropout)
encoder_blocks = []
for _ in range(N) :
encoder_self_attention_block = MultiHeadAttentionBlock(d_model, h,dropout)
feed_forward_block = FeedForwardBlock(d_model,d_ff,dropout)
encoder_block = EncoderBlock(encoder_self_attention_block, feed_forward_block ,dropout)
encoder_blocks.append(encoder_block)
decoder_blocks = []
for _ in range(N) :
decoder_self_attention_block = MultiHeadAttentionBlock(d_model, h,dropout)
decoder_cross_attention_block = MultiHeadAttentionBlock(d_model, h,dropout)
feed_forward_block = FeedForwardBlock(d_model,d_ff,dropout)
decoder_block = DecoderBlock(decoder_self_attention_block, decoder_cross_attention_block, feed_forward_block ,dropout)
decoder_blocks.append(decoder_block)
encoder = Encoder(nn.MouleList(encoder_blocks))
decoder = Decoder(nn.MouleList(decoder_blocks))
projection_layer = ProjectionLayer(d_model , tgt_vocab_size)
transformer = Transformer(encoder, decoder, src_embed, tgt_embed, src_pos, tgt_pos, projection_layer)
for p in transformer.parameters() :
if p.dim() >1 :
nn.init.xavier_uniform_(p)
return transformer
이제 트랜스포머 함수에서 모든 것들을 조립 해주면 된다.
아직 모든 과정을 혼자서 구현하는 것은 조금 어려운 것 같다. 여러번 코드를 읽어보고 이해해보려고 노력해야겠다.
다음 포스팅에서는 트랜스포머 코드를 돌리며 간단한 프로그램을 만들어보자.
끝!
'Papers > 논문 구현' 카테고리의 다른 글
| [논문 구현] Visual Prompt Tuning 구현해보기 (0) | 2023.12.30 |
|---|---|
| [논문 구현] Vision Transformer (0) | 2023.12.30 |
| [논문 구현] AlexNet 구현하기 (By Colab, PyTorch) (1) | 2023.11.16 |
| [논문 구현] VGG16 구현하기 (By Colab, PyTorch) (2) | 2023.11.14 |
| [논문 구현] LeNet-5 구현하기 (By Colab, PyTorch) (1) | 2023.11.12 |

