
Logical Scribbles
[논문 구현] LeNet-5 구현하기 (By Colab, PyTorch) 본문

이번에는 바로 직전 글이었던 LeNet-5 모델을 직접 Google Colab과 Pytorch를 이용하여 만들어 보기로 하자.
https://stydy-sturdy.tistory.com/4
[논문 리뷰] Gradient-Based Learning Applied to Document Recognization(LeNet-5) - 시대 배경 그리고 구조
LeNet-5의 구조만 훑으며 읽고 싶다면 바로 3. LeNet-5를 읽으시면 됩니다. 이번에는 CNN에서의 조상급 논문에 대해 알아보자. 논문을 읽어보기 전, 이 논문이 탄생하게 된 시대 배경을 알고 있으면 더
stydy-sturdy.tistory.com
우선 다시 한번 LeNet-5 모델의 구조를 살펴보자.
※ 본 논문에서는 Loss function을 MSE로 사용했지만, CrossEntropyLoss를 이용하는 것이 더 효과적이기 때문에 Cross entropy loss를 이용하였다. 또한 ouput 파트에서 Euclidian Radial Basis가 아닌 Softmax Function을 사용하였다.
- Layer C1은 convolutional layer이다. input 32*32 데이터를 받아 인풋의 5*5 영역마다 슥슥 넘겨가며(이후 stride의 개념) convolution 한 뒤 한 픽셀을 이루고, 28*28의 feature map이 된다. 이 feature map을 이용하여 2*2 non-overlapping 영역마다 한 픽셀씩 S2 계층으로 sumsampling 된다.
- Layer C3 또한 convolutinal layer로, 이 또한 S2에서 5*5 영역마다 슥슥 넘겨가며 convolution하여 한 픽셀이 된다. Layer S4에서 똑같은 방법으로 subsampling이 된다.
- 마지막으로, fully-connected layers인 C5, F6, OUTPUT은 최종 feature map을 가져와 십진수를 표현하는 10개의 number 중 하나로 촤종 분류 하는 classifier이다.
LeNet-5의 구현을 위해 정의해야 하는 것들은 다음과 같다.
- 모델의 정확도 측정 함수
- 손실 plotting 함수
- Train 함수
- Validate 함수
- Training_loop 함수
- Class LeNet-5
- Hyperparameters
추가적으로, MNIST 데이터도 다운 받아주는 과정을 진행해야 한다.
이제 진짜로 만들어보자! 총 9개의 스텝만 따라오면 10진수를 구분해주는 모델을 만들 수 있다.
1. 모듈 가져오기
import numpy as np
from datetime import datetime
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
import matplotlib.pyplot as plt
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
from pytz import timezone
이 스텝에서는 LeNet-5 모델을 만들고 학습한 뒤 시각화 하기 위한 여러가지 모듈을 import 한다.
2. Hyperparameters 정의
Random_seed = 42 #그냥 정하는 것
Learning_rate = 0.001 # 학습률
Batch_size = 32 # batch size. 이 단위로 학습이 된다.
N_epochs = 15 # epoch 횟수 전체 데이터가 15번 학습된다는 뜻.
Img_size = 32 # 32*32 이미지가 들어갈 것이다.
N_classes = 10 # 0~9 10개의 output class가 있다.
input 이미지 사이즈는 32*32이고, 10진수를 이루는 수는 10개이다.
Batch size는 데이터가 학습되는 단위인데 32로 설정했다. 추후 특별한 설정이 없다면 이 batch size가 전체 데이터셋의 크기를 나누지 못해도 알아서 다시 재활용(?) 하는 듯 하다.
전체적인 데이터가 총 15번 epoch를 갖도록 했다.
2. get_accuracy 함수
# 모델의 정확도를 얻는 함수를 먼저 정의하자
def get_accuracy(model, data_loader, device) :
correct_pred = 0
n = 0
with torch.no_grad() :
model.eval() #batch nomalization, drop out과 같은거 없이! 모델이 평가모드로 전환
for X, y_true in data_loader : #데이터 셋에 있는 인풋
X = X.to(device)
y_true = y_true.to(device)
_, y_prob = model(X) #y_prob은 후에 나올 LeNet-5 모델에서 소프트맥스 함수를 통과한 클래스 확률
_, predicted_labels = torch.max(y_prob,1) #torch.max(y_prob,1) = 열 중에서 가장 높은 값을 뽑아준다. 그럼 그게 예측 라벨이 되겠죠?
n += y_true.size(0)
correct_pred += (predicted_labels == y_true).sum()
return correct_pred.float() / n # 정확히 맞춘것 / 총 개수3. plot_loss 함수
def plot_loss(train_loss, val_loss) :
plt.style.use('grayscale')
train_loss = np.array(train_loss)
val_loss = np.array(val_loss)
fig , ax = plt.subplots(1,1,figsize = (8,4.5))
ax.plot(train_loss, color = 'green' , label = 'Training Loss')
ax.plot(val_loss, color = 'red' , label = 'Validation Loss')
ax.set(title = 'Loss Over Epochs' , xlabel = 'EPOCH' , ylabel = 'LOSS')
ax.legend()
fig.show()
plt.style.use('default')4. train 함수
def train(train_loader, model, criterion, optimizer, device) :
model.train() #모델을 학습 모드로 설정
running_loss = 0 # 초기값 0으로 설정
for X, y_true in train_loader:
optimizer.zero_grad() #역전파시 효과적으로 학습되기 위해 설정 매번 세팅되어야함
X = X.to(device)
y_true = y_true.to(device)
y_hat, _ = model(X)
loss = criterion(y_hat,y_true) #loss를 구함
running_loss += loss.item() * X.size(0) #사이즈를 곱해줘서 전체적인 running loss를 구함
loss.backward() #역전파
optimizer.step() #Gradient descent
epoch_loss = running_loss / len(train_loader.dataset)
return model , optimizer, epoch_loss5. validate 함수
def validate(valid_loader, model, criterion, device):
model.eval()
running_loss = 0
for X, y_true in valid_loader:
X = X.to(device)
y_true = y_true.to(device)
# 순전파와 손실 기록하기
y_hat, _ = model(X) #소프트 맥스 당하기 전 !
loss = criterion(y_hat, y_true)
running_loss += loss.item() * X.size(0)
epoch_loss = running_loss / len(valid_loader.dataset)
return model, epoch_loss6. training_loop 함수
def training_loop(model, criterion, optimizer, train_loader, valid_loader, epochs, device, print_every=1):
# metrics를 저장하기 위한 객체 설정
best_loss = 1e10
train_losses = []
valid_losses = []
# model 학습하기
for epoch in range(0, epochs):
# training
model, optimizer, train_loss = train(train_loader, model, criterion, optimizer, device)
train_losses.append(train_loss)
# validation
with torch.no_grad():
model, valid_loss = validate(valid_loader, model, criterion, device)
valid_losses.append(valid_loss)
if epoch % print_every == (print_every - 1):
train_acc = get_accuracy(model, train_loader, device=device)
valid_acc = get_accuracy(model, valid_loader, device=device)
print(datetime.now(timezone('Asia/Seoul')).time().replace(microsecond=0),'--- ',
f'Epoch: {epoch}\t'
f'Train loss: {train_loss:.4f}\t'
f'Valid loss: {valid_loss:.4f}\t'
f'Train accuracy: {100 * train_acc:.2f}\t'
f'Valid accuracy: {100 * valid_acc:.2f}')
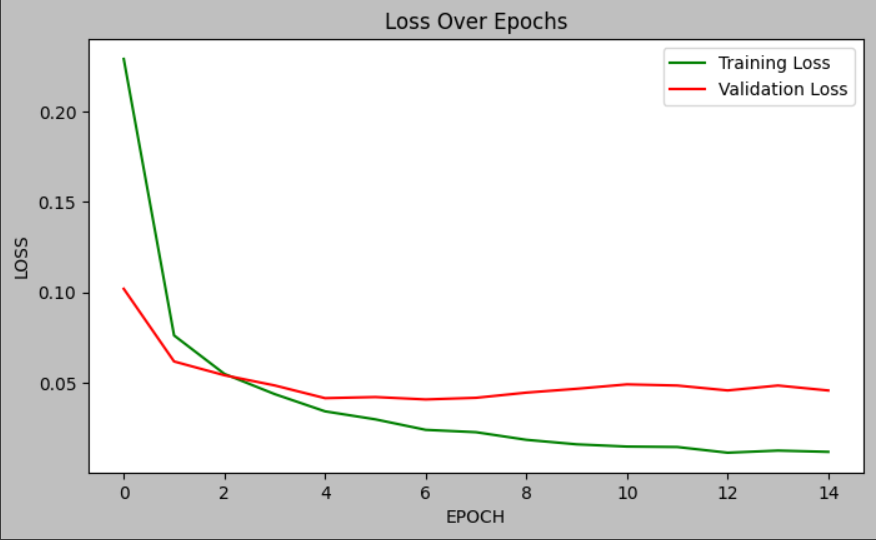
plot_loss(train_losses, valid_losses)
return model, optimizer, (train_losses, valid_losses)7. LeNet-5 class 만들기
class LeNet5(nn.Module):
def __init__(self, n_classes):
super(LeNet5, self).__init__()
self.feature_extractor = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, stride=1), #Bias default
nn.Tanh(),
nn.AvgPool2d(kernel_size=2), # ddefault stride = kernel_size
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, stride=1),
nn.Tanh(),
nn.AvgPool2d(kernel_size=2),
nn.Conv2d(in_channels=16, out_channels=120, kernel_size=5, stride=1),
nn.Tanh()
)
self.classifier = nn.Sequential(
nn.Linear(in_features=120, out_features=84),
nn.Tanh(),
nn.Linear(in_features=84, out_features=n_classes),
) # 120개의 input data를 받아 84개의 output을 배출하고, activation function을 통과한 뒤 84개의 input data를 받아, 10개의 클래스를 output으로
def forward(self, x):
x = self.feature_extractor(x)
x = torch.flatten(x, 1) # 1차원으로 쫙펴준다
logits = self.classifier(x) # classifier에 통과시켜준다
probs = F.softmax(logits, dim=1) # 나온 10개의 값들을 softmax로 확률 구해준다.
return logits, probs
코드를 잘 들여다보면, 논문에서 소개된 구조 그대로 모델을 설계 했음을 알 수 있다. Avgpool2d, Conv2d, Linear 코드 등은 이후 한번에 정리해서 포스팅하도록 하겠다.
8. MNIST dataset 불러오기
# transforms 정의하기
transforms = transforms.Compose([transforms.Resize((32, 32)),
transforms.ToTensor()])
# data set 다운받고 생성하기
train_dataset = datasets.MNIST(root='mnist_data',
train=True,
transform=transforms,
download=True)
valid_dataset = datasets.MNIST(root='mnist_data',
train=False,
transform=transforms)
# data loader 정의하기
train_loader = DataLoader(dataset=train_dataset,
batch_size=Batch_size,
shuffle=True)
valid_loader = DataLoader(dataset=valid_dataset,
batch_size=Batch_size,
shuffle=False)
# 불러온 MNIS data 확인하기
ROW_IMG = 10
N_ROWS = 5
fig = plt.figure()
for index in range(1, ROW_IMG * N_ROWS + 1):
plt.subplot(N_ROWS, ROW_IMG, index)
plt.axis('off')
plt.imshow(train_dataset.data[index], cmap='gray_r')
fig.suptitle('MNIST Dataset - preview');
9. 실행 !
torch.manual_seed(Random_seed)
model = LeNet5(N_classes).to(DEVICE)
optimizer = torch.optim.Adam(model.parameters(), lr=Learning_rate)
criterion = nn.CrossEntropyLoss()
model, optimizer, _ = training_loop(model, criterion, optimizer, train_loader,
valid_loader, N_epochs, DEVICE)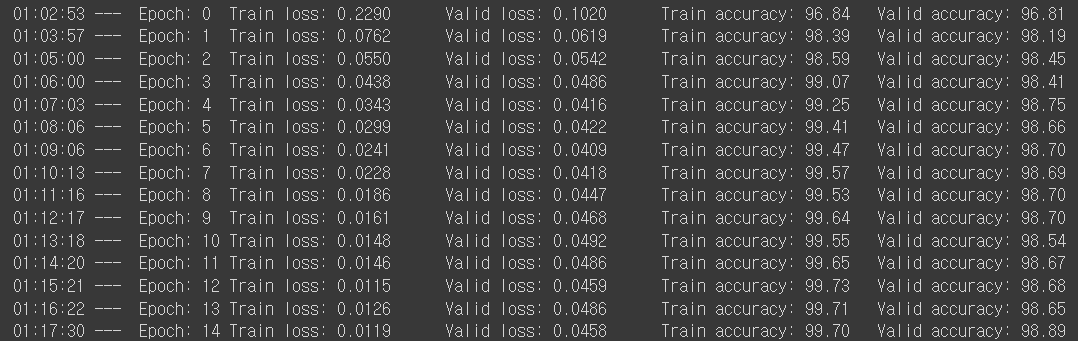
추가적으로 model의 parameter가 궁금하여 1개만 출력해보았다.
for k in model.parameters():
print(k)
break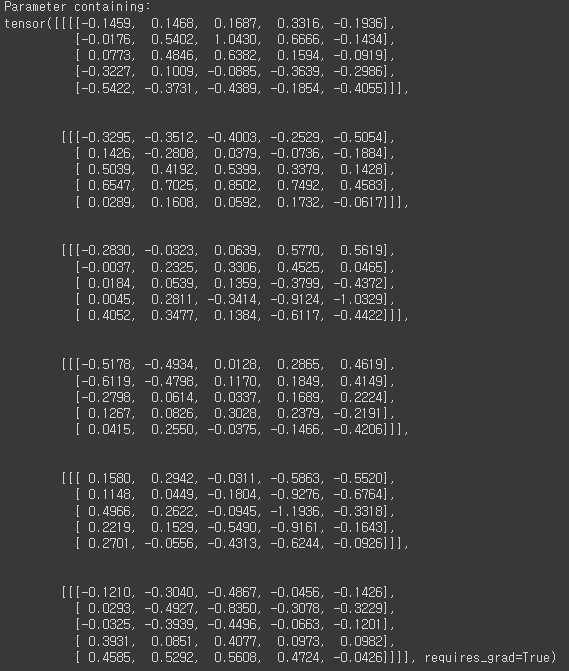
끝 !
'Papers > 논문 구현' 카테고리의 다른 글
| [논문 구현] Visual Prompt Tuning 구현해보기 (0) | 2023.12.30 |
|---|---|
| [논문 구현] Vision Transformer (0) | 2023.12.30 |
| [논문 구현] 트랜스포머(Transformer) 구현하기 (2) | 2023.12.01 |
| [논문 구현] AlexNet 구현하기 (By Colab, PyTorch) (1) | 2023.11.16 |
| [논문 구현] VGG16 구현하기 (By Colab, PyTorch) (2) | 2023.11.14 |


