
Logical Scribbles
[선형대수학] PCA(주성분 분석)란? 본문
오늘은 대망의 PCA에 대해 살펴보자. PCA는 차원을 축소하고 추출하는데에 있어 많은 활용이 되고 있는 방법이다.
PCA를 이해하려면 고유값 분해와 공분산 행렬을 알고 있어야 한다. 또한, 대칭행렬에서의 고유값 분해의 독특한 특징을 알고 있으면 좋다. 너무나도 중요한 토픽이라 대칭행렬의 고유값 분해와 공분산 행렬에 대해 복습하며 시작하겠다. 고유값 분석과 대칭행렬에서의 특징은 아래의 글에 잘 정리가 되어 있다.
[선형대수학] 고유값 분해
지난 포스팅에서 고유값과 고유벡터에 대해 알아보았다. [선형대수학] 고유값(Eigenvalue)과 고유벡터(Eigenvector) 고유값과 고유벡터를 이해하기 위해서는 선형변환과 행렬의 의미에 대해 먼저 알아
stydy-sturdy.tistory.com
1. 대칭행렬의 고유값 분해
대칭행렬의 고유값 분해의 결과는 약간 독특하다. 바로 고유벡터로 만든 행렬이 직교행렬이기 때문이다. 직교행렬의 정의에 의해 직교행렬의 전치(transpose) 또한 직교행렬이기 때문에, 대칭행렬의 고유값 분해의 결과는 직교행렬 두개와 고유값들로 이루어진 대각행렬이 된다.
이것이 의미하는 바는 대칭행렬에 의한 선형변환이 수직 돌리기, 늘리기, 수직 돌리기로 구성된다는 것이다. 그리고 위의 포스팅에서 벡터 x의 이러한 대칭행렬에 의한 선형변환은 x를 직교 벡터들에 내적을 내리는 것과 관련이 있고, 아래의 특이값 분해 포스팅에서 이러한 표현이 데이터 압축과 관련이 있음을 언급한 바 있다.
[선형대수학] 특이값 분해(SVD)의 응용
[선형대수학] 특이값 분해(SVD) 지난 시간에는 고유값 분해에 대해 알아보았다. [선형대수학] 고유값 분해 지난 포스팅에서 고유값과 고유벡터에 대해 알아보았다. [선형대수학] 고유값(Eigenvalue)
stydy-sturdy.tistory.com
2. Covariance Matrix (공분산 행렬)
공분산 행렬은 말그대로 공분산으로 이루어진 행렬이다. 공분산에 대해 먼저 알 필요가 있다.
공분산의 정의는 스칼라인 두 확률변수(X,Y)에 대해 두 변수 사이의 상관관계를 나타내는 스칼라 값이다. 이 상관관계의 판단은 상당히 직관적인데, 공분산이 0보다 크면 X가 커짐에 따라 Y도 커지는 변수라는 것을 의미하고, 공분산이 음수이면 그 반대 상황이 된다. 공분산이 0이라면, 두 확률변수 사이의 어떠한 상관관계도 없다는 것을 의미한다.
수학적으로 공분산은 Cov(X,Y)로 표기한다.

기대값의 성질을 잘 활용하면 최종적으로 맨 마지막 식을 얻을 수 있다.
다음으로 공분산은 다음의 성질들을 갖는다.

기회가 되면 이 공분산에 대해 더 깊게 다루는(공식의 의미하는 바 그리고 성질 유도) 글을 작성하도록 하겠다. 이 포스팅에서는 공분산 행렬에 대해 가볍게 복습하고 넘어가는 느낌으로 소개하겠다.

공분산의 개념을 행렬로 확장 하기 전 위의 두 벡터 표현의 차이를 알아보자. 왼쪽 행렬은 우리가 일반적으로 보는 원소들이 스칼라인 벡터 X이다. 오른쪽 행렬은 랜덤 벡터 X라는 표현을 사용하고 있고, 원소들은 확률 변수들이다.
랜덤 벡터 X에 대한 공분산 행렬은 다음과 같이 정의된다.

행렬을 잘 관찰해보면 Cov(X,X) 공분산 행렬은 대칭행렬이며 정방행렬임을 쉽게 알 수 있다.
이제 이를 바탕으로 랜덤 벡터 X와 Y에 대한 공분산 벡터를 정의하면,

Cov(X,Y)는 다음과 같이 정의할 수 있다. 하지만 랜덤 벡터 X와 Y의 원소의 수가 다를 수 있기 때문에 일반적으로 서로 다른 랜덤 벡터에 대해서 공분산 행렬은 정방행렬과 대칭행렬이 아닐 수 있음을 주의하자.
이제 PCA에 대해 알아볼 준비가 끝났다.
3. PCA(주성분 분석)
PCA는 한마디로 데이터의 차원을 축소하는 수학적 스킬이다. 이에 대해 물음이 생겨야 한다.
"차원을 어떻게 축소할 것인가?"
이 '어떻게'에 대해 알아보기 전, 다음을 생각해보자.
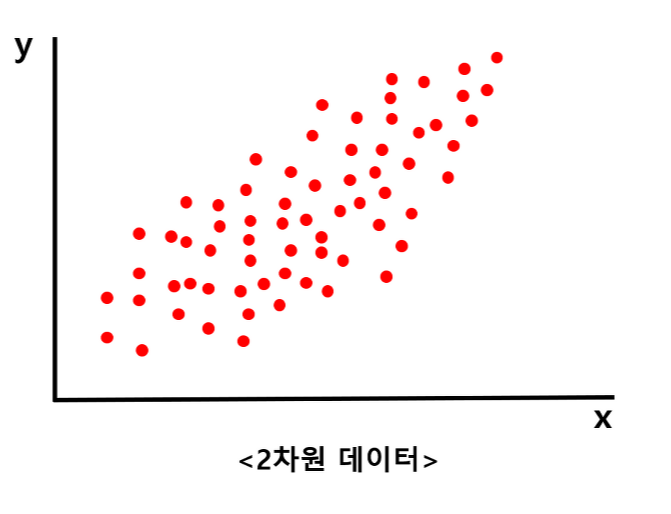
여기 2차원 데이터가 있다. 우리는 계산적인 문제 혹은 여러가지 문제 등으로 인해 2차원 데이터를 1차원 데이터로 축소시키고 싶다. 하지만 여전히 데이터의 분포는 잘 나타내고 싶다. 따라서 데이터의 분포를 가장 잘 나타낼 수 있는 축을 하나 정하고, 그 축에 모든 데이터들을 정사영 시킬 것이다.
위의 2차원 데이터에서 데이터의 분포를 가장 잘 나타낼 수 있는 축은 다음과 같을 것이다.

그렇다면 이 축을 잘 찾아 데이터를 모두 그 축에 정사영 내리면 1차원 상의 데이터가 되고, 이는 기존의 데이터 분포를 잘 설명할 수 있을 것이다. 이렇게 말이다.

여기까지의 과정을 정리해보면
1. 데이터의 분포를 가장 잘 나타내는 축을 찾는다.
2. 그 축에 데이터들을 정사영 시킨다.
3. 축에 정사영 된 데이터들은 여전히 기존 데이터의 분포를 잘 나타낼 것이다. 또한 데이터의 차원이 축소 되었다.
예를 들어 100차원의 데이터가 있을 때 데이터의 분포를 가장 잘 나타내는 축 10개를 찾아 그 축에 정사영 내리면, 여전히 데이터의 분포는 어느 정도 잘 표현할 것이다.
또한 필요한 데이터의 수는 굉장히 줄어들 것이고 계산 효율성, 메모리 문제 등등을 잘 해결할 수 있을 것이다.
굉장히 훌륭한 아이디어다. PCA 끝!
이렇게 끝내면 써먹을 수가 없다. '데이터의 분포를 가장 잘 나타내는 축'을 어떻게 찾느냐 그것이 PCA의 핵심이기 때문이다. 이제는 수학적으로 이 '데이터의 분포를 잘 나타내는 축'이 어떤 특징을 갖는지 살펴보자.
결론부터 말하면 저 축들은 다음과 같은 성질을 갖는다.
- 데이터의 분산이 가장 커지는 방향이다.
- 서로 직교한다 .. ?!
분산이 가장 커지는 방향이라는 것은 직관적으로 그러려니 하겠지만, 그 축들이 직교한다는 것은 직관적으로 이해가 되지 않는다.
우선 '데이터의 분포를 잘 나타낸다'의 의미를 잘 생각해보자.

우리의 데이터 중 대장 데이터를 하나 골랐다고 해보자. 그렇다면 데이터의 분포를 가장 잘 나타내는 축은 저 데이터와의 거리 d가 가장 짧게 되는 축일 것이다. 이제 수학적으로 이 논리를 전개해보자.

친절하게 수식 전개를 하려고 노력하였다. 과정 중 optimization 문제가 등장하는데 이 부분은 아직 잘 모른다면 그냥 넘어가도 될 것 같고, 마지막의 식이 나왔구나 정도만 알아도 될 것 같다.

헉..! 수학의 아름다움 익숙한 식이 나왔다.
다시 이 식이 나오기까지의 과정을 리마인드 해보자.
- 데이터들을 원점으로 옮겨주었다. 이 과정에서 모든 데이터들에서 그들의 평균을 빼주는 작업을 진행했다.
- 대장 점 말고도 모든 점에 대해 거리 d의 합이 최소가 되어야하므로, 모든 d의 합을 minimize하는 문제로 바뀌게 된다.
- 수식을 전개하면 공분산 행렬이 등장하게 되고, uT*Rd*u를 maximize하는 문제로 바뀌게 된다. 이때의 제약조건은 u의 2-norm이 1이어야 한다는 것이다. (크기가 1)
- 제약 조건이 있는 최적화 문제이다. (정확히는 등식 제한조건이다.) 이러한 문제는 라그랑지안으로 풀 수 있다.
- 4번에 의해 Rd*u = λ*u 여야 maximize 된다.
그런데 위의 식은 아주 익숙하다. 바로 고유값 분해할 때 등장했던 식이기 때문이다!
위의 식을 고유값 분해 관점에서 바라보면, 공분산 행렬을 고유값 분해하였을 때의 고유벡터가 u 벡터가 되고, 고유값은 λ가 된다.
따라서 우리가 찾는 축은 바로 공분산 행렬의 고유벡터였다!! 그런데 공분산 행렬은 정방행렬이자 대칭행렬이기 때문에 모든 고유벡터로 이루어진 행렬은 직교행렬이다. 즉 모든 고유벡터들은 직교한다. 따라서 PCA에서의 축들이 직교하는 것이다.
특이값 분해에서 데이터 압축을 다루었었다.

이를 대칭행렬에 적용하면 어떤 행렬이 대칭행렬이면 고유값 분해를 통해 얻는 고유값과 그에 해당하는 고유벡터를 내림차순으로 줄 세웠을 때, 고유값이 큰 것들 몇개만 쏙쏙 선택하면 데이터 압축이 될 것임을 알 수 있다.
이제 PCA에서의 축(이제부터 주축이라 하자)에 대한 두번째 성질에 대한 의문이 해결된다.
- 데이터의 분산이 가장 커지는 방향이다.
- 서로 직교한다 .. ?! : 공분산 행렬의 고유벡터들이 주축이기 때문이다.
공분산 행렬도 대칭행렬이므로, 공분산 행렬도 고유값이 큰 것들 몇개만 쏙쏙 선택하면 데이터 압축이 될 것이다.
이를 PCA라고 한다. '주성분 분석'에서 주성분이란, 분산을 최대로 보존할 수 있는 축과 그 고유값이고, 몇개를 선택하느냐에 따라 데이터 압축의 정도가 달라질 것이다.
끝!
'기초 수학 > 선형대수학' 카테고리의 다른 글
| [선형대수학] PCA(주성분 분석)을 이용한 얼굴 인식 (Python) (0) | 2023.11.22 |
|---|---|
| [선형대수학] 특이값 분해(SVD)의 응용 (0) | 2023.11.21 |
| [선형대수학] 특이값 분해(SVD) (0) | 2023.11.21 |
| [선형대수학] 고유값 분해 (0) | 2023.11.19 |
| [선형대수학] 고유값(Eigenvalue)과 고유벡터(Eigenvector) (0) | 2023.11.18 |



